太子VS汰渍
太子VS汰渍
范文一:线性回归与逻辑回归
线性回归与逻辑回归
1、在描述Logistic 回归之前,我们先要讨论下线性回归(linear regression )。
线性回归假设特征和结果满足线性关系。那什么是回归呢?回归其实就是对已知公式的未知参数进行估计。如,其中x 是参数(特征),用实际已存在的样本
估计出θ的值,(θ为参数),令,有。
我们得到了h (x ),但却不知道h 函数能否有效的表示出真实情况,因此需要对h 函数进行评估,得到损失函数(cost function):
为什么要选择J(θ) 这样的形式作为损失函数呢?我们用概率的角度分析下: 假设预测结果和实际偏差为ε则;
一般假设误差ε为均值为0的正态分布,则x ,y 的概率分布如下:
我们期待的是h (x )预测最准,也就是求最大似然函数最大,因此对最大似然估计公式求导,求导结果是
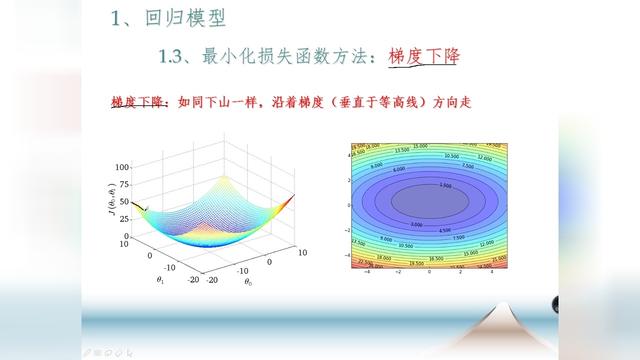
由上知,当J(θ) 取得最小值的时候就是最佳回归,求解的算法有很多,最小二乘法、梯度下降法等等。
梯度下降法是按下面的流程进行的:
1)首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得 J(θ) 按梯度下降的方向进行减少。
最终求得为:
2、简述完线性回归,再聊下Logistic 回归;
对数回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,即先把 特征线性求和,然后使用函数 g(z)将最为假设函数来预测。g(z)可以将连续值映射到 0 和 1上。
同样,这里为什么选择g (z )(sigmoid 函数)这样的形式呢?同样以概率的角度讨论下:
首先要引入一般概率模型;那什么是一般概率模型呢?
伯努利分布bernoulli (Φ),高斯分布当改变Φ或者μ的值,伯努利分布和高斯分布就会发生改变,不同的Φ和μ就形成了分布族;这些分布都是指数分布族的特例,如果一个概率分布可以表示成
这就是一般概率模型。
η:称为特性(自然)参数(natural parameter)
T(y):充分统计量(sufficient statistic)通常T (y )=y;
固定a 、b 、T ,那么就定义了一个概率分布的集合。
Logistic 回归时采用的是伯努利分布,伯努利分布的概率可以表示成
Logistic 回归用来分类 0/1 问题,也就是预测结果属于 0 或者 1 的二值分类问题。这里假设满足伯努利分布,也就是:
我们可以合并下写成:
然后求参数的似然函数:
取对数,得到:
求导,然后更新θ
可以看到Logistic 回归与线性回归是类似,只是
上就是换成了,而实际经过g(z)映射过来的。Logistic 回归本质就是线性回归。
范文二:线性回归与logistic回归
线性回归与 logistic 回归
1. 线性回归要求满足的条件(LINE )
1) 线性 (linear)(自变量与因变量之间必须满足线性关 系)
2) 独立(independent) :各自变量之间关系独立
3)正态(normal )
4)等方差(equal variance)
2. 线性回归和 logistic 回归的区别
1)线性回归要求变量服从正态分布, logistic 回归对 变量分布没有要求。
2) 线性回归要求因变量是连续性数值变量, 而 logistic 回归要求因变量是分类型变量。
3)线性回归要求自变量和因变量呈线性关系,而 logistic 回归不要求自变量和因变量呈线性关系 4) logistic 回归是分析因变量取某个值的概率与自变 量的关系,而线性回归是直接分析因变量与自变量的 关系
范文三:多元线性回归与非线性回归
实验三 多元线性回归与非线性回归
实验目的:
1、 学会多元线性回归的参数估计方法;
2、 掌握多元线性回归的检验方法,包括拟合优度检验、F检验和t检验,尤其是掌握调
整的判断系数和F检验的内容;
3、 掌握非线性回归的参数估计方法,尤其是能够利用EViews软件进行参数估计。 实验内容:
1、下表列出了某地区家庭人均鸡肉年消费量Y与人均可支配收入X、鸡肉价格P1、猪肉价格的相关数据P2,试利用这些资料,设定适当的模型进行回归分析。
(1)、计算相关系数
(2)绘制散点图
2建立模型
2、为了度量投资和劳动投入之间的替代弹性,当今著名的CES(恒定替代弹性)模型形式设定为
ln?V/L??ln?0??1lnW??
其中,V/L表示单位劳动的附加值,L表示投入的劳动,W表示实际工资率。系数?1表示劳动与资本之间的替代弹性。用下表给出的数据,验证估计的弹性是1.324,并且它和1在统计上无显著差异。
范文四:二元逻辑与逻辑回归
二元逻辑把对世界的判断分为非此即彼的对立。
逻辑回归:
首先,通常人们将“Logistic回归”、“Logistic模型”、“Logistic回归模型”及“Logit模型”的称谓相互通用,来指同一个模型,唯一的区别是形式有所不同:logistic回归是直接估计概率,而logit模型对概率做了Logit转换。不过,SPSS软件好像将以分类自变量构成的模型称为Logit模型,而将既有分类自变量又有连续自变量的模型称为Logistic回归模型。至于是二元还是多元,关键是看因变量类别的多少,多元是二元的扩展。
其次,当因变量是名义变量时,Logit和Probit没有本质的区别,一般情况下可以换用。区别在于采用的分布函数不同,前者假设随机变量服从逻辑概率分布,而后者假设随机变量服从正态分布。其实,这两种分布函数的公式很相似,函数值相差也并不大,唯一的区别在于逻辑概率分布函数的尾巴比正态分布粗一些。但是,如果因变量是序次变量,回归时只能用有序Probit模型。有序Probit可以看作是Probit的扩展
范文五:logistic 回归与线性回归的比较
1 logistic回归
logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。以胃癌病情分析为例,选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群必定具有不同的体征与生活方式等。因此因变量就为是否胃癌,值为“是”或“否”,自变量就可以包括很多了,如年龄、性别、饮食习惯、幽门螺杆菌感染等。自变量既可以是连续的,也可以是分类的。然后通过logistic回归分析,可以得到自变量的权重,从而可以大致了解到底哪些因素是胃癌的危险因素。同时根据该权值可以根据危险因素预测一个人患癌症的可能性。
1.1 logistic回归概述
logistic回归是一种广义线性回归(generalized linear model),因此与多重线性回归分析有很多相同之处。它们的模型形式基本上相同,都具有w?x+b,其中w和b是待求参数,其区别在于他们的因变量不同,多重线性回归直接将w?x+b作为因变量,即y =w?x+b,而logistic回归则通过函数L将w?x+b对应一个隐状态p,p =L(w?x+b),然后根据p 与1-p的大小决定因变量的值。如果L是logistic函数,就是logistic回归,如果L是多项式函数就是多项式回归。
logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释,多类可以使用softmax方法进行处理。实际中最为常用的就是二分类的logistic回归。
Logistic回归模型的适用条件
1 因变量为二分类的分类变量或某事件的发生率,并且是数值型变量。但是需要注意,重复计数现象指标不适用于Logistic回归。
2 残差和因变量都要服从二项分布。二项分布对应的是分类变量,所以不是正态分布,进而不是用最小二乘法,而是最大似然法来解决方程估计和检验问题。
3 自变量和Logistic概率是线性关系
4 各观测对象间相互独立。
原理:如果直接将线性回归的模型扣到Logistic回归中,会造成方程二边取值区间不同和普遍的非直线关系。因为Logistic中因变量为二分类变量,某个概
率作为方程的因变量估计值取值范围为0-1,但是,方程右边取值范围是无穷大或者无穷小。所以,才引入Logistic回归。
Logistic回归实质:发生概率除以没有发生概率再取对数。就是这个不太繁琐的变换改变了取值区间的矛盾和因变量自变量间的曲线关系。究其原因,是发生和未发生的概率成为了比值,这个比值就是一个缓冲,将取值范围扩大,再进行对数变换,整个因变量改变。不仅如此,这种变换往往使得因变量和自变量之间呈线性关系,这是根据大量实践而总结。所以,Logistic回归从根本上解决因变量要不是连续变量怎么办的问题。还有,Logistic应用广泛的原因是许多现实问题跟它的模型吻合。例如一件事情是否发生跟其他数值型自变量的关系。
注意:如果自变量为字符型,就需要进行重新编码。一般如果自变量有三个水平就非常难对付,所以,如果自变量有更多水平就太复杂。这里只讨论自变量只有三个水平。非常麻烦,需要再设二个新变量。共有三个变量,第一个变量编码1为高水平,其他水平为0。第二个变量编码1为中间水平,0为其他水平。第三个变量,所有水平都为0。实在是麻烦,而且不容易理解。最好不要这样做,也就是,最好自变量都为连续变量。
spss操作:进入Logistic回归主对话框,通用操作不赘述。
发现没有自变量这个说法,只有协变量,其实协变量就是自变量。旁边的块就是可以设置很多模型。
“方法”栏:这个根据词语理解不容易明白,需要说明。
共有7种方法。但是都是有规律可寻的。
“向前”和“向后”:向前是事先用一步一步的方法筛选自变量,也就是先设立门槛。称作“前”。而向后,是先把所有的自变量都进来,然后再筛选自变量。也就是先不设置门槛,等进来了再一个一个淘汰。
“LR”和“Wald”,LR指的是极大偏似然估计的似然比统计量概率值,有一点长。但是其中重要的词语就是似然。
Wald指Wald统计量概率值。
“条件”指条件参数似然比统计量概率值。
“进入”就是所有自变量都进来,不进行任何筛选
将所有的关键词组合在一起就是7种方法,分别是“进入”“向前LR”“向前
Wald”"向后LR"“向后Wald”“向后条件”“向前条件”
下一步:一旦选定协变量,也就是自变量,“分类”按钮就会被激活。其中,当选择完分类协变量以后,“更改对比”选项组就会被激活。一共有7种更改对比的方法。
“指示符”和“偏差”,都是选择最后一个和第一个个案作为对比标准,也就是这二种方法能够激活“参考类别”栏。“指示符”是默认选项。“偏差”表示分类变量每个水平和总平均值进行对比,总平均值的上下界就是"最后一个"和"第一个"在“参考类别”的设置。
“简单”也能激活“参考类别”设置。表示对分类变量各个水平和第一个水平或者最后一个水平的均值进行比较。
“差值”对分类变量各个水平都和前面的水平进行作差比较。第一个水平除外,因为不能作差。
“Helmert”跟“差值”正好相反。是每一个水平和后面水平进行作差比较。最后一个水平除外。仍然是因为不能做差。
“重复”表示对分类变量各个水平进行重复对比。
“多项式”对每一个水平按分类变量顺序进行趋势分析,常用的趋势分析方法有线性,二次式。
1.2 logistic回归主要用途
logistic回归一是寻找危险因素
正如上面所说的寻找某一疾病的危险因素等。
logistic回归二是预测
如果已经建立了logistic回归模型,则可以根据模型,预测在不同的自变量情况下,发生某病或某种情况的概率有多大。
logistic回归三是判别
实际上跟预测有些类似,也是根据logistic模型,判断某人属于某病或属于某种情况的概率有多大,也就是看一下这个人有多大的可能性是属于某病。
这是logistic回归最常用的三个用途,实际中的logistic回归用途是极为广泛的,logistic回归几乎已经成了流行病学和医学中最常用的分析方法,因为它与多重线性回归相比有很多的优势,以后会对该方法进行详细的阐述。实际上有
很多其他分类方法,只不过Logistic回归是最成功也是应用最广的。
1.3 logistic回归案例分析
关于富士康跳楼曲线的Logistic回归分析。
正常人都能知道这绝对不是偶然,至于这背后有什么?我一开始也不甚清楚。 然后一篇突如其来的实验报告被发还给我,然后看着我亲手绘制的磁滞回线。有了主意。
首先,我查到了有记载以来,所有富士康员工自杀的日期:
列出如下表格:(以07年6月18号,第一例自杀案例为原点,至今(10年5月25日)1072天)
可见这是一个指数增长的曲线。
对此我认为自杀和流行病一样,自杀也是一种病,而且是一种可以传染的疾病。
因此其增长曲线与对数增长很接近。
对其做指数函数拟合:
General model Exp2:
f(x) = a*exp(b*x) + c*exp(d*x)
Coefficients (with 95% confidence bounds):
a = 7.569e-007 (-6.561e-006, 8.075e-006)
b = 0.01529 (0.006473, 0.0241)
c = 1.782 (0.5788, 2.984)
d = 0.001075 (2.37e-005, 0.002125)
Goodness of fit:
SSE: 8.846
R-square: 0.9684
Adjusted R-square: 0.9598
RMSE: 0.8968
可见相关度0.96也是非常高的。
然而和所有疾病一样,一旦其事件引起了人们的关注,则各方的反馈作用,将阻碍其继续上升。
因此,和很多流行病分析一样,该曲线很有可能呈S型。对于该曲线的分析,使用Logistic回归。
首先我们假设Logis(B,x)=F(x),之中B为参数数组,则由经验和可能的微分方程关系,回归曲线应该为
S(x)=m*Logis(B,x+t)/(n+Logis(B,x+t))格式
由于当Logis(B,x)较小时S(x)=Logis(B,x),则可以认为f(x)的参数可以直接引入S(x)作为一种近似,而对于m,n的确定,我以1为间隔,画出m*n=40*20的所有曲线,
选出其中最吻合的的一条(m=22 n=20 t=50):
1.4 logistic
回归其他信息
由此可以见,富士康的跳楼人数最终会稳定在在22人左右。。。由此仍然不会超过全国平均跳楼率。
对此曲线的分析,我们借鉴微生物生长曲线的方法,将其分为:
缓慢期,对数期,稳定期,衰亡期
缓慢期,富士康员工虽然受到很大的工作压力,可是其自身的心理并没有崩溃,因此跳楼这种事件发生频率很少,而且呈线性关系,说明没有跳楼者受到别的跳楼者的影响。
对数期,富士康员工由于受到工厂巨大的工作压力,以及来自社会各方的压力,甚至加上上级的欺压,心理防线渐渐崩溃,无处发泄。而一旦有想不开者跳楼,则为其提供了一个发泄的模板,这种情况下,很容易有相同经历的员工受到跳楼者的影响,从而一个接一个的跳楼自杀。目前的富士康正处于此时期。
稳定期,由于社会、媒体各方面的关注以及社会、广大人民对工厂的压力,工厂不得不做出改变,员工的心理压力渐渐得到释放,从而员工跳楼轻生频率会很快下降。
衰亡期,这个……由于资料长期保存,不小心遗失;或者某机关的辟谣;或者所有人的健忘,导致跳楼人数被修正,被减少。
2 线性回归
线性回归,是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w'x+e,e为误差服从均值为0的正态分布。
在统计学中,线性回归(Linear Regression)是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。(这反过来又应当由多个相关的因变量预测的多元线性回归区别,[引文需要],而不是一个单一的标量变量。)
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
回归分析中有多个自变量:这里有一个原则问题,这些自变量的重要性,究竟谁是最重要,谁是比较重要,谁是不重要。所以,spss线性回归有一个和逐步判别分析的等价的设置。
原理:是F检验。spss中的操作是“分析”~“回归”~“线性”主对话框方法框中需先选定“逐步”方法~“选项”子对话框
如果是选择“用F检验的概率值”,越小代表这个变量越容易进入方程。原因是这个变量的F检验的概率小,说明它显著,也就是这个变量对回归方程的贡献越大,进一步说就是该变量被引入回归方程的资格越大。究其根本,就是零假设分水岭,例如要是把进入设为0.05,大于它说明接受零假设,这个变量对回归方程没有什么重要性,但是一旦小于0.05,说明,这个变量很重要应该引起注意。这个0.05就是进入回归方程的通行证。
下一步:“移除”选项:如果一个自变量F检验的P值也就是概率值大于移除中所设置的值,这个变量就要被移除回归方程。spss回归分析也就是把自变量作为一组待选的商品,高于这个价就不要,低于一个比这个价小一些的就买来。所以“移除”中的值要大于“进入”中的值,默认“进入”值为0.05,“移除”值为0.10
如果,使用“采用F值”作为判据,整个情况就颠倒了,“进入”值大于“移除”值,并且是自变量的进入值需要大于设定值才能进入回归方程。这里的原因就是
F检验原理的计算公式。所以才有这样的差别。
结果:如同判别分析的逐步方法,表格中给出所有自变量进入回归方程情况。这个表格的标志是,第一列写着拟合步骤编号,第二列写着每步进入回归方程的编号,第三列写着从回归方程中剔除的自变量。第四列写着自变量引入或者剔除的判据,下面跟着一堆文字。
这种设置的根本目的:挑选符合的变量,剔除不符合的变量
注意:spss中还有一个设置,“在等式中包含常量”,它的作用是如果不选择它,回归模型经过原点,如果选择它,回归方程就有常数项。这个选项选和不选是不一样的。
在线性回归中,数据使用线性预测函数来建模,并且未知的模型参数也是通过数据来估计。这些模型被叫做线性模型。最常用的线性回归建模是给定X值的y的条件均值是X的仿射函数。不太一般的情况,线性回归模型可以是一个中位数或一些其他的给定X的条件下y的条件分布的分位数作为X的线性函数表示。像所有形式的回归分析一样,线性回归也把焦点放在给定X值的y的条件概率分布,而不是X和y的联合概率分布(多元分析领域)。
线性回归是回归分析中第一种经过严格研究并在实际应用中广泛使用的类型。这是因为线性依赖于其未知参数的模型比非线性依赖于其位置参数的模型更容易拟合,而且产生的估计的统计特性也更容易确定。
线性回归有很多实际用途。分为以下两大类:
1. 如果目标是预测或者映射,线性回归可以用来对观测数据集的和
X的值拟合出一个预测模型。当完成这样一个模型以后,对于一个新增的X值,在没有给定与它相配对的y的情况下,可以用这个拟合过的模型预测出一个y值。这是比方差分析进一步的作用,就是根据现在,预测未来。虽然,线性回归和方差都是需要因变量为连续变量,自变量为分类变量,自变量可以有一个或者多个,但是,线性回归增加另一个功能,也就是凭什么预测未来,就是凭回归方程。这个回归方程的因变量是一个未知数,也是一个估计数,虽然估计,但是,只要有规律,就能预测未来。
2. 给定一个变量y和一些变量X1,...,Xp,这些变量有可能与y相关,
线性回归分析可以用来量化y与Xj之间相关性的强度,评估出与y不相
关的Xj,并识别出哪些Xj的子集包含了关于y的冗余信息。
线性回归模型经常用最小二乘逼近来拟合,但他们也可能用别的方法来拟合,比如用最小化“拟合缺陷”在一些其他规范里(比如最小绝对误差回归),或者在桥回归中最小化最小二乘损失函数的惩罚.相反,最小二乘逼近可以用来拟合那些非线性的模型.因此,尽管“最小二乘法”和“线性模型”是紧密相连的,但他们是不能划等号的。
2.1 数据组说明线性回归
以一简单数据组来说明什么是线性回归。假设有一组数据型态为 y=y(x),其中
x={0, 1, 2, 3, 4, 5}, y={0, 20, 60, 68, 77, 110}
如果要以一个最简单的方程式来近似这组数据,则用一阶的线性方程式最为适合。先将这组数据绘图如下
图中的斜线是随意假设一阶线性方程式 y=20x,用以代表这些数据的一个方程式。以下将上述绘图的MATLAB指令列出,并计算这个线性方程式的 y 值与原数据 y 值间误差平方的总合。
>> x=[0 1 2 3 4 5];
>> y=[0 20 60 68 77 110];
>> y1=20*x; % 一阶线性方程式的 y1 值
>>sum_sq = sum((y-y1).^2); % 误差平方总和为 573
>>axis([-1,6,-20,120])
>>plot(x,y1,x,y,'o'), title('Linear estimate'), grid
如此任意的假设一个线性方程式并无根据,如果换成其它人来设定就可能采用不同的线性方程式;所以必须要有比较精确方式决定理想的线性方程式。可以要求误差平方的总和为最小,做为决定理想的线性方程式的准则,这样的方法就称为最小平方误差(least squares error)或是线性回归。MATLAB的polyfit函数提供了从一阶到高阶多项式的回归法,其语法为polyfit(x,y,n),其中x,y为输入数据组n为多项式的阶数,n=1就是一阶的线性回归法。polyfit函数所建立的多项式可以写成
从polyfit函数得到的输出值就是上述的各项系数,以一阶线性回归为例n=1,
所以只有二个输出值。如果指令为coef=polyfit(x,y,n),则coef(1)= , coef(2)=,...,coef(n+1)= 。注意上式对n 阶的多项式会有 n+1 项的系数。看以下的线性回归的示范:
>> x=[0 1 2 3 4 5];
>> y=[0 20 60 68 77 110];
>>coef=polyfit(x,y,1); % coef代表线性回归的二个输出值
>> a0=coef(1); a1=coef(2);
>>ybest=a0*x+a1; % 由线性回归产生的一阶方程式
>>sum_sq=sum((y-ybest).^2); % 误差平方总合为 356.82
>>axis([-1,6,-20,120])
>>plot(x,ybest,x,y,'o'), title('Linear regression estimate'), grid
2.2 线性回归拟合方程 编辑
线性回归最小二乘法 一般来说,线性回归都可以通过最小二乘法求出其方程,可以计算出对于y=bx+a的直线,其经验拟合方程如下:
其相关系数(即通常说的拟合的好坏)可以用以下公式来计算:
2.3 线性回归结果分析
虽然不同的统计软件可能会用不同的格式给出回归的结果,但是它们的基本内容是一致的。以STATA的输出为例来说明如何理解回归分析的结果。在这个例子中,测试读者的性别(gender),年龄(age),知识程度(know)与文档的次序(noofdoc)对他们所觉得的文档质量(relevance)的影响。
输出:
Source | SS df MS Number of obs = 242
-------------+------------------------------------------ F ( 4, 237) = 2.76
Model | 14.0069855 4 3.50174637 Prob> F = 0.0283
Residual | 300.279172 237 1.26700072 R-squared = 0.0446
------------- +------------------------------------------- Adj R-squared = 0.0284
Total | 314.286157 241 1.30409194 Root MSE = 1.1256
------------------------------------------------------------------------------------------------ relevance | Coef. Std. Err. t P>|t| Beta
---------------+-------------------------------------------------------------------------------- gender | -.2111061 .1627241 -1.30 0.196 -.0825009
age | -.1020986 .0486324 -2.10 0.037 -.1341841
know | .0022537 .0535243 0.04 0.966 .0026877
noofdoc | -.3291053 .1382645 -2.38 0.018 -.1513428
_cons | 7.334757 1.072246 6.84 0.000 .
-------------------------------------------------------------------------------------------
2.4 线性回归输出
这个输出包括以下几部分。左上角给出方差分析表,右上角是模型拟合综合参数。下方的表给出了具体变量的回归系数。方差分析表对大部分的行为研究者来讲不是很重要,不做讨论。在拟合综合参数中, R-squared 表示因变量中多大的一部分信息可以被自变量解释。在这里是4.46%,相当小。
2.5 线性回归回归系数
一般地,要求这个值大于5%。对大部分的行为研究者来讲,最重要的是回归系数。年龄增加1个单位,文档的质量就下降 -.1020986个单位,表明年长的人对文档质量的评价会更低。这个变量相应的t值是 -2.10,绝对值大于2,p值也<>
2.6 线性回归回归方程的误差
线性回归方法1:利用离差平方和
,
,
其中
,代表y的平方和;
是相关系数,代表变异被回归直线解释的比例;
就是不能被回归直线解释的变异,即SSE。
根据回归系数与直线斜率的关系,可以得到等价形式:
,其中b为直线斜率
线性回归方法2:利用预测值
,其中
是实际测量值,
是根据直线方程算出来的预测值
1. 线性回归斜率b的不确定度
法1:用
法2:把斜率b带入
2. 线性回归截距a的不确定度