


 低调的二蛋
低调的二蛋
范文一:大数据库
南京邮电大学 计算机学院
《大型数据库技术》
实验三:MySQL 数据库进阶开发
姓名:焦敬尧 班级:计科2班 学号:B13040233
2016 年 4 月 15日 星期五
说明:斜体需要输出的部分。
1 MySQL 的存储过程和函数
1.1 创建企业销售系统的数据库,命名为salesdb
1.2 创建一张商品销售表,命名为salerecords ,包括如下字段:商品ID ,商品名称,销
售单价,销售数量。
以上不需要截图。
create database salesdb;
Use saledb;
create table salerecords(id int not null auto_increment primary key,name varchar(10) not null,price int not null,salenum int not null);
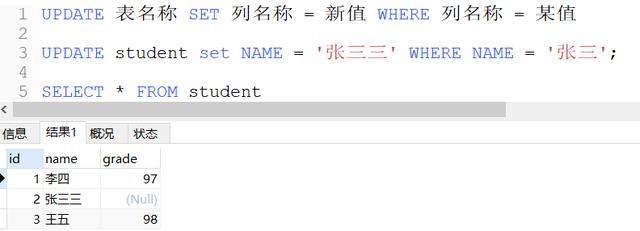
1.3 创建一个存储过程,名称自订,通过输入商品ID ,商品名称,销售单价,销售数量往
表中插入一条记录。
Delimiter //
Create procedure sale_insert(in in_id int, in in_name varchar(10),in in_price int,in in_salenum int)
Begin
Insert into salerecords(id,name,price,salenum)values(in_id,in_name,in_price,in_salenum); End
//
delimiter ;
Call sale_insert(1,'water',16,55);
Call sale_insert(2,'mood',17,95);
Call sale_insert(3,'stone',22,15);
Select * from salerecords;
输出截图:(包括存储过程定义,调用三次存储过程,以及表的查询结果)
1.4 创建一个存储过程,名称自订,通过输入商品名称往表中插入100条记录。其中,所
插入第一条记录的商品ID 由现有表中商品ID 的最大值+1构成,后续记录中商品ID
依次递增1。所插入第一条记录的商品价格与现有表中商品价格的最小值相同,后续
记录的商品价格依次递增1。商品销售数量随机生成。
Delimiter //
Create procedure sale_insert_100(in in_name varchar(10))
Begin
Declare i int;
Declare maxid int;
Declare minprice int;
Set i=0;
Select max(id) from salerecords into maxid;
Select min(price) from salerecords into minprice;
While i<100>
Set maxid=maxid+1;
Set minprice=minprice+1;
set i=i+1;
Insert into salerecords(id,name,price,salenum)values(maxid,in_name,minprice,rand()*100); End while;
End
//
Delimiter;
Call sale_insert_100(‘meat ’);
Select*from salerecords limit 10;
输出截图:(包括存储过程定义,表中前10条查询结果)
1.5 创建一个存储过程,名称自定,通过输入商品ID 的最小值,最大值,将表中商品ID
处于(最小值,最大值) 范围内,且为偶数的记录删除,包括最小值与最大值本身。
此处不考虑商品ID 不存在的情况,在实验时请选择1.4中创建的商品ID 范围的子
集。
Delimiter //
Create procedure delect_from_min_to_max(in in_min_id int,in in_max_id int) Begin
Delete from salerecords
Where id>=in_min_id
And id<>
End
//
Delimiter ;
Call delect_from_min_to_max(4,8);
Select * from salerecords limit 10;
输出截图:
1.6 创建两个事件调度器,第一个每3秒往1.2的表中插入一条记录,第二个每30秒清空
1.2的表中的所有记录。
Create event insert_every_3record
On schedule every 3 second
Do
Insert into salerecords(name,price,salenum)values(‘ajiao ’,16,2300);
Create event clear_second
On schedule every 30 second
Enable
Do
Truncate table salerecords;
Select count(*)from salerecords;
输出截图:(只需要截取两个事件调度器的定义,以及在三个不同时刻查询表中记录count (*)的结果。)
2 MySQL 的触发器
2.1 定义一个触发器,实现如下功能,在往1.2的表中插入记录的时候,将记录同时也插
入到一张新的表sale_backup.
Create table sale_backup(id int not null auto_increment primary key,name varchar(10) not null,price int not null,salenum int not null);
Delimiter //
Create trigger trigger_insert after insert on salerecords
For each row
Begin
Insert into sale_backup(id,name,price,salenum)
values(new.id,new.name,new.price,new.salenum);
End;
//
Delimiter ;
Call sale_insert_100(‘meat ’);
Select*from sale_backup limit 10;
输出截图:(包括触发器定义,以及调用了1.4的存储过程后sale_backup的前10条记录)
3 MySQL 的事务控制
3.1 启动一个事务往1.2的表中插入任意三条记录,提交在第二条和第三条记录中定义一
个savepoint ,在插入完成后回滚到定义的savepoint 。
Start transaction;
Insert into salerecords(name,price,salenum)values(‘蒙牛’,2.5,30);
Insert into salerecords(name,price,salenum)values(‘伊利’,3,69);
Savepoint insert_point;
Insert into salerecords(name,price,salenum)values(‘三鹿’,1,59);
Rollback to insert_point;
Commit;
输出截图:(包括整个操作过程)
3.2 简述读锁和写锁的区别
读锁是共享的,互不阻塞,读取同一资源互不影响,写锁排他,一个写锁会阻塞其他的读写操作。
4 MySQL 的分区
4.1 分别使用range 分区(自行决定区间)和hash 分区创建对应与1.2中表的分区。 Alter table salerecords
Partition by range (id)(partition p0 values less than (10),partition p1 values less than (20),partition p2 values less than (30),partition p3 values less than (40));
Alter table salerecords
Partition by hash(id)
Partitions 10;
输出截图:
4.2 插入100条记录后,确认分区中的记录分布情况。 输出截图:
范文二:大数据库
达内大数据课程明细
第一阶段 :
(以 Tetris 项目贯穿)
模块 课程内容 项目介绍
Java 语言 基础 算法基础、常用数据结
构、企业编程规范
掌握常见的数据结构和实用算法;培养 良好的企业级编程习惯。
Java 面向 对象 面向对象特性:封装、继
承、多态等,面向对象程
序设计,基础设计模式
等。
掌握面向对象的基本原则以及在编程实 践中的意义; 掌握 Java 面向对象编程基 本实现原理。
实训项目一:Tetris 项目开发
第二阶段 :
(以 T-DMS V1项目贯穿)
模块 课程内容 项目介绍
JDK 核心 API 语言核心包、异常处理、 常
用工具包、集合框架。
熟练掌握 JDK 核心 API 编程技术; 理 解 API 设计原则;具备熟练的阅读 API 文
档的能力; 为后续的课程学习打下坚 实的语言基础。
JavaSE 核心 异常处理、多线程基础、 IO
系统、 网络编程、 Java 反射
机制、
JVM 性能调优(JVM 内存结
构剖析、 GC 分析及调优、 JVM
内存
参数优化) 、 Java 泛型、 JDK
新特性。
熟练掌握 JavaSE 核心内容,特别是 IO 和多线程; 初步具备面向对象设计 和编
程的能力; 掌握基本的 JVM 优化策略。 实训项目二:T-DMS V1项目开发
第三阶段 :
(以 T-DMS V2项目贯穿)
模块 课程内容 项目介绍
SQL 语言 SQL 语句基础和提高、 SQL 语句
调优。
熟练的掌握 SQL 语句;掌握一定 数据库查询技巧及 SQL 语句优化 技巧。
Oracle 数据 库 Oracle 体系结构及系统管理、
Oracle 数据库高级编程、数据
库设计基础。
掌握 Oracle 体系结构及核心编 程技术。
JDBC JDBC 核心 API (Connection 、
Statement 、 ResultSet )、
JDBC 优化技术(缓存技术、批
处理技术、连接池技术)。
理解 JDBC 作为规范的设计原则; 熟练掌握 JDBC API;具备使用 JDBC 对数
据库进行高效访问的能力。
XML XML 语法、 XML 解析 (SAX 、 DOM ) 、
Dom4j 组件、 Digester
组件。
熟练掌握 XML 语法规则; 理解 DOM 模型; 熟悉 Java 对 XML 的各种解 析方
式。
实训项目三:T-DMS V2项目开发
第四阶段 :
(以 T-NetCTOSS 电信计费系统贯穿)
模块 课程内容 项目介绍
HTML/CSS HTML 基本文档结构、
掌握 CSS 基础语法、
关于 HTML 文档块、 链
接、列表、表格、表
单等。
掌握 HTML 基本原理; 掌握 CSS 各种选择器 及常见样式设置;熟练使用 HTML 常用元 素。
JavaScript 核心 JavaScript 语言基
础 (数据类型、 函数、
对象、 闭包) 、 JavaDOM
编程、事件模型、
JavaScript 面向对
象编程。
深入理解 JavaScript 语言原理; 熟练的使 用 JavaScript 对 HTML DOM 进行编程; 熟 练掌握 JavaScript 对象对象封装技巧, 为 后续的 JavaScript 学习打下坚实的基础。
Servlet/JSP Servlet 生命周期及 透彻理解 Servlet 核心原理;熟练掌握
Servlet 服务器、 Tomcat 部署配置、 JSP 语
法、 自定义标记、 JSTL 和 EL 表达式、 JSP 新 特性、 Java Web 设计 模式。 Servlet API ; 透彻理解 JSP 引擎工作原理; 透彻理解标记库原理;熟悉常见的 Java Web 设计模式;为后续的 JavaWeb 开发打 下坚实的理论基础。
Ajax Ajax 基础、 XHR 对象、
Ajax 设计模式、 JSON
技术
掌握 Ajax 的基本通信原理; 掌握基于 XML 和 JSON 的 Ajax 数据规则。
JavaScript 框架 JQuery 、 JQuery 插
件、 ExtJS 。
掌握 JQuery 核心 API ;了解 JQuery 基本 设计原则;了解多种 JQuery 插件; 掌握 DWR 的基本原理及应用技巧。
Struts2 Struts2核心控制流
程、 Ognl 、 Action 、
Interceptor 、
Result 、
FreeMarker 、 Struts2
标记库、 Struts2扩
展、 Struts2应用技
巧
(输入验证、消息国
际化、文件上传和下
载、防止重复提交
等)。
熟练掌握 Struts2核心要件,特别是 Interceptor 和 Result ;掌握基于模板技 术的 Struts2 UI组件;掌握基于 Ognl 的 数据共享方式、掌握 Struts2各种定制及 扩展方式;熟练掌握基于 Struts2的 Web 开发技巧。
实训项目四:T-NetCTOSS 电信计费系统项目开发
第五阶段 :
(
企业应用 开发部署 环境 Linux 高级命令集脚本
编程、远程登录、 Ant 、
单元测试技术、 Maven
构建技术、 SVN 应用技
术。
熟练掌握基于 Linux 系统的操作技能;可 以熟练的完成应用的部署工作;可以熟练 的使用开发部署工具。
Struts2 Struts2核心控制流程、
Ognl 、 Action 、
熟练掌握 Struts2核心要件,特别是 Interceptor 和 Result ;掌握基于模板技
Interceptor 、 Result 、 FreeMarker 、 Struts2标记库、 Struts2扩展、 Struts2应用技巧 (输入验证、消息国际 化、文件上传和下载、 防止重复提交等)。 术的 Struts2 UI组件;掌握基于 Ognl 的 数据共享方式、掌握 Struts2各种定制 及扩展方式; 熟练掌握基于 Struts2的 Web 开发技巧。
持久层框 架技术 ORM 概念、 Hibernate 核
心 API 、 Hibernate 实体
映射技术、 Hibernate
关系映射技巧、 HQL 查
询、 OSCache 及
Hibernate 缓存技术。
掌握 JQuery 核心 API ; 了解 JQuery 基本设 计原则;了解多种 JQuery 插件;
掌握 DWR 的基本原理及应用技巧。
Spring 技 术 Spring Ioc基础、 Ioc
注入技巧、对象高级装
配(自动装配、
模板装配、组件扫描特
性、 Factor yBean、对
象生命周期)、
Spring AOP原理、
AspectJ 、 Spring JDBC
支持、 Spring 事
务及安全管理; Spring
整合 Hibernate 、 Spring
整合 Struts ,
SpringMVC 技术。
深入理解 Ioc 和 AOP 的基本原理和实现方 式; 熟练掌握 SpringIoc 及 AOP 实现方式; 熟练掌握 Spring 事务管理;熟练掌握 Spring 与其他组件的整合技术。
实训项目五:
第六阶段 :
(
Hadoop 集群安装及原理; hdfs 命令行操作; Java 操作 hdfs 的 常用 API 接口;动态添加删除数据节点。
HBase 集群安装及原理; Hbase 命令行操作; Java 操作 Hbase 的常用 API 接口。
Hadoop 高级 MapReduce 开发; Flume 抽取日志; Hive 安装及命令行操 作及 JDBC 操作;通过 Sqoop 进行 Hive 和 MySQL之间的
数据交换; MaHout 入门;
分布式集群管理 zookeeper 集群安装及原理及 Java 常用 操作接口。
大数据交换 Kafka 集群安装及原理; Kafka 常用 java 接口 API ; 远程 RPC 方案 Thrift ;开源 ETL 工具 Kettle 。
大数据查询 基于 Lucene 查找 Hbase 中的数据;基于 Redis 缓存数据 提升平台性能。
大数据项目实践 系统需求获取及平台架构设计;数据存储底层搭建以及 与 WEB 对接;提升用户体验;通过数据分析发觉用户需 求。
范文三:大数据内存数据库与NoSql数据库
内存数据库与 NoSql 数据库 Tianmj@ibmsp.com.cn
给力大数据系列之
传统 RDBMS 关系型数据库
? 表结构(列,行)
? 关联(OneToMany,ManyToOne,OneToOne )
? ACID:
? 原子性 (Atomicity) 整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在 中间某个环节。
? 一致性(Consistency ) 在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。 ? 隔离性(Isolation ) 两个事务的执行是互不干扰的,一个事务不可能看到其他事务运行时中 间某一时刻的数据。
? 持久性(Durability ) 在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之 中,并不会被回滚。
传统 RDBMS 表结构
◆有限列
◆受限于字段类型、长度
◆空字段占用空间问题
◆全表扫描问题
缺点:
传统 RDBMS 表关联
◆有限关联; ◆性能问题; ◆一系列限制;
传统关系型数据库 IO
面临的挑战
核心业务正在面临数据计算扩展能力的挑战
增加或减少 Web 和
应用服务器 数据的扩展只能依赖于移到更大 处理能力的机器上 Web 和应用层很容易扩展及虚拟化, 节点可以灵活地增加或减少 共享文件系统能够被虚拟 化,按需进行增长 Web 层
应用层
数据库层
存储层
负载均衡器
内存数据库
? 内存数据库,顾名思义就是将数据放在内存中直接操作的数据库。相对于磁 盘,内存的数据读写速度要高出几个数量级,将数据保存在内存中相比从磁 盘上访问能够极大地提高应用的性能。
? 同时,内存数据库抛弃了磁盘数据管理的传统方式,基于全部数据都在内存 中重新设计了体系结构,并且在数据缓存、快速算法、并行操作方面也进行 了相应的改进,所以数据处理速度比传统数据库的数据处理速度要快很多 。 (双通道 DDR3-1333可以达到 ,一般磁盘约 ),
DDR3-1333可以达到 )。
? 内存数据库的最大特点是其“主拷贝”或“工作版本”常驻内存,即活动事 务只与实时内存数据库的内存拷贝打交道。显然,它要求较大的内存量,但 并非任何时刻整个数据库都存放在内存,即内存数据库系统还是要处理 I/O
NoSQL 概念
? No (NoSQL = Not Only SQL),指的是非关系型的数据库。 ? 关系型数据库中的表都是存储一些格式化的数据结构,每个元 组字段的组成都一样,即使不是每个元组都需要所有的字段,但 数据库会为每个元组分配所有的字段,这样的结构可以便于表与 表之间进行连接等操作,但从另一个角度来说它也是关系型数据 库性能瓶颈的一个因素。
? 非关系型数据库以键值对存储,它的结构不固定,每一个元组可 以有不一样的字段,每个元组可以根据需要增加一些自己的键值 对,这样就不会局限于固定的结构,可以减少一些时间和空间的 开销。
NoSQL 特点
它们可以处理超大量的数据 。
它们运行在便宜的 PC 服务器集群上。
PC 集群扩充起来非常方便并且成本很低,避免了“ sharding ” 操作的复杂性 和成本。
它们击碎了性能瓶颈。
通过 NoSQL 架构可以省去将 Web 或 Java 应用和数据转换成 SQL 格式的时间, 执行速度变得更快。
没有过多的操作。
关系数据库提供了无可比拟的功能集合,而且在数据完整性上也发挥绝 对稳定,但对于某些企业的具体需求可能不需要那么多。
NoSQL 产品
? Redis 内存数据库
? MongoDB 文档数据库
? Neo4j 图数据库
? Hbase 列数据库
? Hadoop 分布式计算模型 ? GemFire 商用内存数据库 ? timesTen Oracle 商用内存数据库
Redis
Redis 与 Memcached
? 共同特征
? 都是 key-value 形式的内存数据库
? 都是 NoSQL 家族的数据管理解决方案
? 都基于同样的 key-value 数据模型
? 所有数据全部放在内存中 (这也是适用于缓存的原因 ) ? 性能得分不分伯仲 , 包括数据吞吐量和延迟等指标 ? 都是成熟的、广受开源项目欢迎的 key-value 存储系统
Redis
? 有硬盘存储支持的内存数据库,
? 支持 Master-slave 复制
? 虽然采用简单数据或以键值索引的哈希表,但也支持复杂操作,例如 ZREVRANGEBYSCORE 。 ? INCR & co (适合计算极限值或统计数据)
? 支持 sets (同时也支持 union/diff/inter)
? 支持列表(同时也支持队列;阻塞式 pop 操作)
? 支持哈希表(带有多个域的对象)
? 支持排序 sets (高得分表,适用于范围查询)
? Redis 支持事务
? 支持将数据设置成过期数据(类似快速缓冲区设计)
? Pub/Sub允许用户实现消息机制
? 最佳应用场景:适用于数据变化快且数据库大小可遇见(适合内存容量)的应用程序。 ? 例如:股票价格、数据分析、实时数据搜集、实时通讯。
Redis
? 内存数据库
? 单核
? value 限制 512M
? 多种 value 类型 , 游戏用途使用私有的序列化协议 (例如 protobuf) ? 支持落地 (bgsave)
? 用户 : 新浪 , 淘宝 , Flickr, Github
? 应用场景 : 适合读写都很高 , 数据处理复杂等
Redis 速度
? SET 操作每秒钟 110000 次, GET 操作每秒钟 81000 次, ? 服务器配置如下:
Linux 2.6, Xeon X3320 2.5Ghz.
Redis 用武之地
? 使用 Redis 作为缓存 , 通过调优缓存内容 , 系统效率能获得极大提升。
? 很明显 Redis 的优势在于缓存管理。 缓存通过某种数据回收机制 (data eviction mechanism)在必要时将旧数据从内存中删除 , 为新数据腾出空间。 Redis 允许细粒度控制过期缓存 , 有 6种不同的策略可供选择。 Redis 还采用了一些更复杂的内存管理方 法和回收策略。
? Redis 对缓存的对象提供更大的灵活性。 是二进制安全的【即不丢数据 , 与编码无关】。 Redis 提供 6种数据类型 , 使缓存以及 管理缓存变得更加智能和方便 。
? Redis 通过 Hash 来存储一个对象的字段和值 , 并可以通过单个 key 来管理它们。
? 而使用 Redis Hash 的方式 , 可以大幅度降低资源消耗并提高性能。 Redis 的其他数据类型 , 如 List 或者 Set, 可用来实现更复杂的 缓存管理模式。
? 160多个命令中的大部分都可以用来进行数据操作 , 所以通过服务端脚本调用进行数据处理成为现实。 这些内置命令和用 户脚本可以让你直接灵活地处理数据任务 , 而无需通过网络将数据传输给另一个系统进行处理。
? Redis 提供了可选 /可调整的数据持久化 , 目的是为了在 崩溃 /重启后可以快速加载缓存。
? 最后 , Redis提供主从复制 (replication)。 Replication 可用于实现高可用的 cache 系统 , 允许某些服务器宕机的情况下也能提供 不间断的服务。
? 需要使用缓存来提高应用系统性能时 ,Redis 和 Memcached 是最佳的产品级解决方案。 但考虑到其丰富的功能和先进的设计 , 绝大多数时候 Redis 都应该是你的第一选择。
Hbase 特点
? 特点:支持数十亿行 X 上百万列
? 在 BigTable 之后建模
? 采用分布式架构 Map/reduce
? 对实时查询进行优化
? 高性能 Thrift 网关
? 通过在 server 端扫描及过滤实现对查询操作预判 ? 支持 XML, Protobuf, 和 binary 的 HTTP
? Cascading, hive, and pig source and sink modules? 基于 Jruby (JIRB )的 shell
? 对配置改变和较小的升级都会重新回滚
? 不会出现单点故障
? 堪比 MySQL 的随机访问性能
Hbase 存储特点
? 假如系统中有一个 User 表,如果按照传统的 RDBMS 的话, User 表 中的列是固定的,比如 schema 定义了 name,age,sex 等属性, User 的属性是不能动态增加的。
? 但是如果采用列存储系统,比如 Hbase ,那么我们可以定义 User 表, 然后定义 info 列族, User 的数据可以分为:info:name= zhangsan,info:age=30,info:sex=male等,如果后来你又想增加另外 的属性,这样很方便只需要 info:newProperty就可以了。
MongoDB
? DB-Engines 公布了 2014年年度最受欢迎数据库管理系统
? 自从公布此榜单两年以来, MongoDB 已经二度成为最受欢迎的 NoSQL 数据库。 MongoDB 最大的特点是它支持的查询语言非常大, 其语法有点类似于面向对象的查询语言,几乎可以实现类似关系 数据库单表查询的绝大部分功能,而且还支持对数据建立索引, 这也是其如此受欢迎的原因之一
? 在开源的、面向文档的数据库中, MongoDB 经常被誉为具有 RDBMS 功能的 NoSQL 数据库。
? MongoDB 还带有交互式 shell ,这使得访问其数据存储变得简单, 且其对于分块的即装即用的支持能够使高可伸缩性跨多个节点。
MongoDB
i7四核 8G , insert 一次 20万,循环 10次,总共 200万数据用时 65秒。 Insert 语句及存储示例:
>db.person.insert({name:
>db.person.insert({name:
> db.person.find();
{
{
> db.person.find({
{
MongoDB 特点
? 特点:保留了 SQL 一些友好的特性(查询,索引)。
? Master/slave复制(支持自动错误恢复,使用 sets 复制)
? 内建分片机制
? 支持 javascript 表达式查询
? 可在服务器端执行任意的 javascript 函数
? update-in-place 支持比 CouchDB 更好
? 在数据存储时采用内存到文件映射
? 对性能的关注超过对功能的要求
? 采用 GridFS 存储大数据或元数据(不是真正的文件系统)
? 最佳应用场景:适用于需要动态查询支持;需要使用索引而不是 map/reduce功能;需要对大数据库 有性能要求;
? 1.Mongodb bson文档型数据库,整个数据都存在磁盘中, hbase 是列式数据库,集群部署时每个 familycolumn 保存在单独的 hdfs 文件中。
? 2.Mongodb 主键是“ _id”, 主键上面可以不建索引 , 记录插入的顺序和存放的顺序一样, hbase 的主键就 是 row key,可以是任意字符串 (最大长度是 64KB ,实际应用中长度一般为 10-100bytes) ,在 hbase 内部, row key保存为字节数组。存储时,数据按照 Row key的字典序 (byte order)排序存储。
? 3.Mongodb 支持二级索引,而 hbase 本身不支持二级索引
? 4.Mongodb 支持集合查找,正则查找,范围查找,支持 skip 和 limit 等等,是最像 mysql 的 nosql 数据库, 而 hbase 只支持三种查找:通过单个 row key访问,通过 row key的 range ,全表扫描
? 5.mongodb 的 update 是 update-in-place ,也就是原地更新,除非原地容纳不下更新后的数据记录。而 hbase 的修改和添加都是同一个命令:put ,如果 put 传入的 row key已经存在就更新原记录 , 实际上 hbase 内部也不是更新,它只是将这一份数据已不同的版本保存下来而已, hbase 默认的保存版本的历史数 量是 3。
? 6.mongodb 的 delete 会将该行的数据标示为已删除,将该删除记录数据置空,这种方法会提升性能。 MongoDB 与 Hbase
? 7.mongodb 和 hbase 都支持 mapreduce ,不过 mongodb 的 mapreduce 支持不够强大,如果没有 使用 mongodb 分片, mapreduce 实际上不是并行执行的
? 8.mongodb 支持 shard 分片, hbase 根据 row key自动负载均衡,这里 shard key和 row key的选取 尽量用非递增的字段,尽量用分布均衡的字段,因为分片都是根据范围来选择对应的存取 server 的,如果用递增字段很容易热点 server 的产生,由于是根据 key 的范围来自动分片的, 如果 key 分布不均衡就会导致有些 key 根本就没法切分,从而产生负载不均衡。
? 9.mongodb 的读效率比写高, hbase 默认适合写多读少的情况。
? 10.hbase 采用的 LSM 思想 (Log-Structured Merge-Tree),就是将对数据的更改 hold 在内存中, 达到指定的 threadhold 后将该批更改 merge 后批量写入到磁盘,这样将单个写变成了批量写, 大大提高了写入速度,但降低了读的性能。
mongodb 采用的是 mapfile+Journal思想,如果记录不在内存,先加载到内存,然后在内存中 更改后记录日志,然后隔一段时间批量的写入 data 文件,这样对内存的要求较高,至少需要 容纳下热点数据和索引。
MongoDB 与 Hbase
Neo4j
图数据库
Neo4j 图数据库
Neo4j
图数据库
Neo4j 图数据库
? node(节点 )
? 每个节点可以和多个节点之间建立多个关系 (relationship)
? 单个节点可以设置多个 (Key,Value)的 properties 属性的键值对 ? relationships(关系 )
? 每个关系都会包含一个 startNode 和 endNode
? 每个关系可以设置多个 (Key,Value)的 properties 属性的键值对 ? 可以为关系定义对应的关系类型 (RelationshipType)
* DynamicRelationshipType 动态关系类型
* XXXRelationshipType 静态关系类型 (实现了 RelationshipType 接口 )
Neo4j
图数据库
Neo4j 特点
? 可独立使用或嵌入到 Java 应用程序
? 图形的节点和边都可以带有元数据
? 很好的自带 web 管理功能
? 使用多种算法支持路径搜索
? 使用键值和关系进行索引
? 为读操作进行优化
? 支持事务(用 Java api)
? 使用 Gremlin 图形遍历语言
? 支持 Groovy 脚本
? 支持在线备份,高级监控及高可靠性支持使用 AGPL/商业许可
?
? 最佳应用场景:适用于图形一类数据。这是 Neo4j 与其他 nosql 数据库的最显著区别 ? 例如:社会关系,公共交通网络,地图及网络拓谱
HADOOP
HADOOP
GemFire
? GemFire 的第一个版本发布于 2002年 3月份,当时它还属于一家独 立的公司 GemStone Systems. 后来 GemStone System 这家公司被 VMware 给收购了, GemFire 也被整合到了 VMware Vfabric产品线。 请注意, VMWare 当时也收购了 Redis 项目。
? 在 2013年 4月 EMC 与 VMware/GE合资成立一家新公司 Pivotal , VMware 慷慨的贡献出了它的 vfabric 产品线,以及它收购的一些开 源项目。
? 目前, GemFire 的商业版权已经属于 Pivotal 了。顺便说一句, Redis 的创始人 Salvatore Sanfilippo现在也供职于 Pivotal.
1. 分布式数据存储
? 稳定而高性能的的基于内存的数据数据存储
? 灵活的 Cache 部署策略:点对点(peer to peer);客户端/服务端(client server);多集群
(multiple clusters)的本地或远程数据同步,支持数据高性能灾备和双活
? 灵活的 Region (数据对象集或者可理解为表)分布式处理:同一集合数据(可理解为一个表的数据) 可以整集多点同步或切割后不同点保存,并支持数据实时再平衡(rebalance )既数据分隔保存后若加入 新的空闲服务器,数据可以在不重启服务的情况下重新切割和平衡数据,从而达到真正的数据在线动态 延展
? 具有持续性的数据高可用性和容错性:各个分散的数据点可以配置一个或多个基于内存的热备数据 点,当主数据点宕机的情况下,其中一个热备点就会提升称为主数据点,同时可以继续在空闲机器上创 建备份点,从而达到数据的持续的可用性。同时数据可以通过配置同步或异步地持续化到本地硬盘,或 者到指定的数据库或文件中。
? 数据地客户端缓存:客户端可以将最常用数据缓存一个备份与本地,进一步加快效能
? 在线数据备份
? 数据全内存和部分内存策略:通过配置可以将数据全部存入内存,或者通过将非频繁使用数据挤出 策略(LRU )来将部分频繁适用数据保存于内存中达到成本效益最大化
? 内置资源优化器用以降低 JAVA GC所带来的延迟,支持单个大容量 Cache 点(一般服务器可配置超过 40GB 内存的 Java heap size)
? 安全支持:基于用户和角色的数据访问,数据传输渠道加密(SSL ) ? 数据存取除 key -value 简单 cache 支持外,支持复杂数据对象和关系 存储
? 丰富的 OQL (类 SQL )的查询语言支持
? 支持数据单记录或批处理
? 本地或分布式事务处理
? Map-Reduce 并行查询:同一查询命令可并行发送到各 Cache 点 (Map ),结果集自动在客户端汇合(Reduce )
? 智能定点查询:查询命令在包含数据特征如主键值时,查询命令会 自动命中数据点
Load Balancer
在 NoSQL 领域,利用弹性的数据网格计算架构,为业务系统提供高并发、低延迟的 数据处理能力,同时保障数据的最终一致性和完整性
GemFire 典型的几种部署方式
Shopping cart state
management High performance OLTP?Shared data grid populated by
multiple data feeds and serving
many clients
?Ability to execute app logic in
clients and/or within the data
grid itself
使用场景
?商业银行信用卡用户行为实时分析及附加服务的提供 ?商业银行信用卡反欺诈实时分析和监控
?商业银行客户关系管理系统报表查询及分析
?商业银行主机系统日间 /夜间批量对账
?投资银行外汇交易
?投资银行金融衍生品风险评估和定价
?大型在线订票网站火车票余额查询
?大型航空信息提供商机票信息查询和产品定价 ?交通运输行业实时道路车辆监控
?娱乐网站实时在线广告推送
?等等
12306
12306
? 12306从 2012年 3月开始改造,采用 10几台 X86
服务器 实现了以前数十台 小型机 的余票计算和
查询能力,单次查询的最长时间从之前的 15秒左右下降到 0.2秒以下,缩短了 75倍以上。 2012年春运的极端高流量并发情况下,系统几近瘫痪。而在改造之后,支持每秒上万次的 并发查询,高峰期间达到 2.6万个查询 /秒吞吐量
pv 就是访问者打开了你的几个页面
12306
12306
? 高流量方面,主要涉及低延迟的余票查询。 Gemfire 支持类 Map-Reduce 并行处理,能够按车 次将余票、共用定义等数据拆分成多个独立的计算单元 , 对余票查询中最耗时的共 用定义部 分做预先处理 , 生成查询缓存。当余票数据发生变化时 , 系统会动态更新查询缓存。有了预处 理及数据同步过程维护的动态查询缓存 , 单次查询可以控制在 10ms-300ms 之间 , 同时 10分钟 的固有延迟也不存在了。
? 订单查询系统改造,在改造之前的系统运行模式下,每秒只能支持 300-400个 QPS 的吞吐量, 高流量的并发查询只能通过分库来实现。改造之后,可以实现高达上万个 QPS 的吞吐量,而 且查询速度可以保障在 20毫秒左右。新的技术架构可以按需弹性动态扩展,并发量增加时, 还可以通过动态增加 X86服务器来应对,保持毫秒级的响应时间。
? 在以往的春运期间, 12306售票系统部署 Gemfire 集群在 2个 ,提供服务。
? 在 2015年春运购票高峰之前,考虑到超大并发会造成网络流量大以及阻塞的问题,特别在 阿里云建立一个 ,由阿里云提供“虚拟机”的租赁服务,将基于 Gemfire 实现余票 查询功能的系统以及 Web 服务部署在这些虚拟机上,以分流“余票查询”请求,解决因为 高峰期超高并发造成的网络阻塞问题,以进一步提高服务品质。为此, 12306在 2014年下半 年在阿里云做了小规模的部署和调试。 2015年春运购票高峰期的 12306高效平稳运行,也验 证了混合架构的可行性。
范文四:超市管理数据库设计-《数据库原理与应用》课程大作业
内容与要求
1. 请结合软件类专业课程实验教学环节设计数据库~实现实验教学的有效管理~具体功能应包括但不限于:
,1,教师可以根据不同课程编辑和发布实验内容,
,2,学生可以浏览实验内容~同时完成作品的提交,
,3,学生可以在规定时间内填写、修改和提交实验报告,
,4,教师可以通过应用系统批改实验报告~并提交成绩,
,5,学生可以查询个人实验成绩,
2. 给出数据库设计各个阶段的详细设计报告~包括:
,1,需求分析
,2,概念结构设计
,3,逻辑结构设计
,4,物理结构设计与实施
3. 写出应用系统的主要功能设计,
4. 写出收获和体会~包括已解决和尚未解决的问题~进一步完善的设想和建议,
5. 独自完成作业~有雷同的平分得分,
6. 也可以自行设计课题。
超市管理数据库设计 学号:141530153 姓名:江浩
目 录
1 绪论 ...................................................................................................................................1 2 应用系统功能设计 ..............................................................................................................2
2.1 业务操作流程...........................................................................................................2
2.2 系统功能设计...........................................................................................................5 3 数据库设计.........................................................................................................................7
3.1 需求分析..................................................................................................................7
3.1.1数据流图项 ....................................................................................................7
3.1.2数据字典 ........................................................................................................9
3.2 概念结构设计......................................................................................................... 10
3.3 逻辑结构设计......................................................................................................... 11
3.4 物理结构设计与实施 .............................................................................................. 13
3.4.1建立信息表 .................................................................................................... 13
3.4.2创建数据库 .................................................................................................... 15 4 结束语.............................................................................................................................. 20
4.1 收获和体会 ............................................................................................................ 20
4.2 总结与展望 ............................................................................................................ 20
超市管理数据库设计 学号:141530153 姓名:江浩
1 绪论
以前,有很多超市的管理水平停留在纸介质的基础上,这样的机制已经不能适应时代的发展要求了,因为这样的管理模式浪费了许多人力、物力和财力。如今,随着信息时代的发展,以前的那些落后的管理模式已经被以计算机为基础的信息管理模式所替代。
现代大型超市普遍使用以计算机为基础的信息管理模式,这样能够有效提高销售速度和服务水平。管理者可以利用超市管理系统,准确把握每一种商品的销售动态,防止商品缺货或积压,另外,可以通过超市管理系统精准地查询每天每月的商品销售情况,可以间接的分析各种商品销售变化规律,商品销售结构、居民消费变化等,从而为合理进货、经营、加工、库存、销售等提供科学的决策依据。
超市管理系统充分运用计算机管理信息技术,建立数据库,对超市的进销存过程进行详细分析,实现了对超市的人力、进货、销售和库存的科学管理。
本设计主要是通过在网络上查询最新超市信息管理方案、到周边中型、大型超市现场考察、对相关工作人员调查等方式来确定本次设计的信息管理系统方案。
在设计中,对相关数据利用sql server 2008建立数据库,管理人员可以利用数据库对超市工作人员信息、商品信息、销售信息、库存信息、采购信息进行查询、修改、删除、插入等操作,也可以按照不同条件对数据库内的数据进行筛选、比较等,使系统自动生成符合条件的信息报告;对于员工,可以登录个人的账户查询个人信息以及进项相关操作;对于顾客,可以在计算机上上查询自己想要的商品,而会员则可以登录个人账户,了解个人信息和积分等。
1
超市管理数据库设计 学号:141530153 姓名:江浩
2 应用系统功能设计
2.1 业务操作流程
超市信息管理系统分为不同模块来管理,可以以管理员、采购员、供货元、收银员、顾客为实体对象来划分模块,其余的小的实体对象还包括仓库管理员,售货员、维修工等,主要功能模块和数据流层图如下所示:
1、管理员对库存信息库的查询管理、对员工信息库的信息的录入查询管理、查看商品销售信息、了解货架信息库、查询超市会员信息库等,除此之外,可需要还需要对采购员提供的采购信息、供货员提供的供货信息进行核算校对等
查询 采库存信息库 批准 购
员 录入、修改、查询 员工信息库
请示、回复 管数查询、统计 理据商品销售库 员 库
查询 请示、回复 货架信息库
供
查询 货批准 会员信息库 员
图1 管理数据流程图
2、采购员登陆查询个人信息、对库存信息的查询、并打印清单、请示管理人员、采购商品、入库后仓库管理员对库存信息库录入数据等。
2
超市管理数据库设计 学号:141530153 姓名:江浩
管
理员 请示、回复 员 工
查询个人信息 信
息批准 库 采
购
员 库 完成 查询库存信息、统计
存
信供录入采购信 息货 购买 息 库 商
查询 仓管员
图2 采购数据流程 3、供货员可以登录账户查询个人信息库,可以查询货架信息库统计信息,向管
理员请示,经批准后到仓库提货,同时仓库管理人员将供货信息录入库存信息库,
供货员同样将供货信息录入货架信息库。
员
工 查询个人信息 信
息请示、回复
库 管供 理货员 员 货查询货架信息、统计 架 批准 信
息 录入供货信息
库 查询 仓管员
图3 供货数据流程
4、收银员可以登陆个人账户查询个人信息,查询货架信息,结算货物之时可以
3
超市管理数据库设计 学号:141530153 姓名:江浩
查询是否是超市会员,结算之后修改货架信息库的数据,将销售数据录入商品信息库,然后给顾客打印发票。如果顾客需要办理会员,收银员可以登记会员信息,将会员信息写入会员信息库。
员 工
信 息
库
查询个人信息
货 架查询货架信息、统计、录入 信 发票 息 库
供 顾 货客 员 购买
商 录入销售数据 品
销
售 库
会员信息查询、录入 会
员 信
息
库
图4 售货数据流程
5、顾客分为普通客户和会员两部分,都可以查询货架商品信息,会员可以登陆账户查询个人信息。
4
超市管理数据库设计 学号:141530153 姓名:江浩
会
员查询个人信息 信
息会购买 库 员
收查询商品信息 顾银客 货员 架普发票 信通 息查询商品信息
库
图5 顾客数据流程
2.2 系统功能设计
大型超市管理系统是决策者和管理者针对超市的大量业务处理工作采用计算机进行的全面现代化管理,主要包括人力资源管理、商品采购管理、商品销售管理、顾客信息管理等几个模块。方便实现用户数据的更新、维护查询、统计、打印等相关业务的需要。具体的系统功能描述如下:
1、人力资源管理。本模块主要存储管理员、收银员、销售员、采购员、维修工等职称的工作人员履历信息,包括工号、姓名、性别、职称、身份证号、籍贯、学历等信息。另外还存储顾客会员的会员号、会员名、性别、积分等情况。
主要实现的功能是:通过信息管理系统界面对上述信息数据输入、按照条件查询、计算统计、打印信息(输出信息)、维护数据等,可以让管理者及时了解超市的人员分布情况,查询工作人员的各种信息,了解超市工作人员的整体情况。
2、商品采购管理。采购商品需要知道,商品的商品号、商品名、商品现有数量、采购数量、提供商号、提供商名、提供商地址、提供商电话、进价、售价等信息。
实现功能:查询统计各种商品的数量。打印采购信息清单。
5
超市管理数据库设计 学号:141530153 姓名:江浩
3、库存信息管理。需要知道商品号、商品名称、现有数量、应有数量、仓库号、仓库名,仓库地址、仓库管理员。
此模块需要实现查询信息、统计商品数量、维护仓库商品数据的功能。可以每天查询商品的应有量、现有量、每种商品的存放时间等。
查询是需要按照不足的商品号和商品名称的信息生成商品数量不足的信息报告,报告包括商品号、商品名、来源(供应商、供应商名)等信息。
4、商品销售管理。建立商品销售数据表,存储商品号、商品名、销售时间、单价、数量、总价等信息。
每一位顾客购买商品后系统会自动留下上述信息,收银员并将其写入数据库,此外,收银台给每一位顾客打印发票,包括超市名称、收银台号、商品名称、单价、商品数量、总价等信息。
此外,收银员和供货员可以查询货架商品信息,查询商品号、商品名称、应有量、现有量等信息。根据此信息筛选出货架商品数量不足的商品号、商品名、仓库号等信息的供货清单。
最后,可以查询每天的商品销售情况,包括各种商品的商品号、商品名称、单价、销售数量、总价,也可以计算出当天的全部收入情况。
5、顾客查询信息。 所有的顾客可以通过超市的计算机查询系统来查询超市货架是否有自己需要的商品,可以查询商品的商品号、商品名称、商品数量等顾客需要的信息。
计算机查询系统除了工作人员可以通过输入工号和密码来进入系统查询个人信息和修改密码之外,也允许超市的会员通过输入会员号和密码来登入个人账户查看积分等信息和修改密码的功能。
6
超市管理数据库设计 学号:141530153 姓名:江浩
3 数据库设计
随着现代科学技术的发展,计算机技术已经渗透到各个领域,成为各行业必不可少的工具,特别是Internet技术的推广和信息高速公路的建立,使IT产业在市场竞争中越发显示出其独特的优势,步入信息化时代,有巨大的数据信息等待加工处理和传输,这使得对数据库的进一步开发和利用显得尤为迫切。
国内市场的一些中小型超市,它们在信息化过程中的步伐要落后于大中型超市,而对于这些企业的资源管理,信息的存储和处理也显得迫切需要,要适应市场竞争,就需要有高效的处理方式和管理方法,因此加快超市的信息化进程是必不可少的。 3.1 需求分析
3.1.1数据流图项
员工信息。针对员工(管理员、采购员、供货员、收银员、售货员、维修工)需要将各种信息存放到员工信息库当中,可对其进行查询、插入、删除、更新等操作,员工实体信息主要包括工号、姓名、性别、身份证号、籍贯、学历、等,实体图如下所示:
身份性职学 证号 别 称 历 姓 名 籍
贯
工
号 员工
图6 员工实体图
2、会员信息。针对会员需要将其个人信息和积分情况记录入案,可写入会员信息库当中,需要会员号、会员名、性别、积分等信息,具体实体图如下所示:
7
超市管理数据库设计 学号:141530153 姓名:江浩
性积 会会别 分 员员
名 号 性 别
会员
图7 会员实体图
3、供应商信息。针对商品提供商需要将其商品供应信息记录入库,包括供货商号、供货商名、地址、电话等信息,具体实体图如下所示:
供供 地电货货 址 话 商商
名 号
性 别
供货商
图8 供货商实体图
4、商品信息。需要商品信息写入库存信息库,包括商品号、商品名、进价、售价、应有量、现有量、提供商号、入库日期等信息,具体实体图如下所示:
8
超市管理数据库设计 学号:141530153 姓名:江浩
售 进 应现 有有价 价 量 量 商
品 供货名 商号
商采购品日期 商品 号
图9 商品实体图
3.1.2数据字典
(A)数据项:
数据项名 数据项含义 数据别名 数据类型 与其他数据项的关系 Wno 员工工号编号 工号 Char(6) Wname 员工姓名 姓名 Char(20) Wsex 员工性别(男、女) 性别 Char(5) Wna 员工职位 职称 Char(20) Wid 员工身份证号 身份证号 Char(18) Wed 员工学历水平 学历 Char(5) Wadd 员工籍贯地址 籍贯 Char(50) Gno 会员号编号 会员号 Char(6) Gname 会员姓名名 会员名 Char(20) Gsex 性别(男女) 性别 Char(5)
积分数量 积分 Gshu Char(10) Pno 供货编号 供货商号 Char(6) Pname 供货商名 供货商名 Char(20) Ptel 供货商电话 电话 Char(11) Padd 供货商地址 地址 Char(50) Mno 商品编号 商品号 Char(6) Mname 商品名称 商品名 Char(20) Mbid 商品进价 进价 float Mprince 商品售价 售价 float Mshould 商品应有量 应有量 int
9
超市管理数据库设计 学号:141530153 姓名:江浩
Mamount 商品现有量 现有量 int
供货商编号号 供货商号 同供货商信息供货商号 Pno Char(6)
Mtime 入库日期 入库日期 Char(20) Cno 采购单号 采购单号 Char(6) Wno 工号 工号 Char(6) 同员工工号 Pno 采购提供商号 提供商号 Char(6) 同供货商信息供货商号 Mno 采购商品号 商品号 Char(6) 同供货商信息供货商品号 Mname 采购商品名 商品名 Char(20) 同供货商信息供货商品名 Camount 采购数量 数量 Char(6) Dno 供货单号 供货单号 Char(6) Wno 工号 工号 Char(6) 同员工工号 Sno 货架号 货架号 Char(6) Mno 商品号 商品号 Char(6) 同供货商信息供货商号 Mname 商品名 商品名 Char(20) 同供货商信息供货商名 Damount 数量 数量 Char(6) Eno 交易号 交易号 Char(6) Mno 商品号 商品号 Char(20) 同供货商信息供货商号 Mname 商品名 商品名 float 同供货商信息供货商名
售价 售价 Mprince int Mamount 数量 数量 float Total 总价 总价 Char(20) Etime 销售时间 销售时间 Char(6)
(B)数据结构:
数据结构名 数据含义说明 组成
Winfo 员工信息 Wname、Wna、Wsex、Wid、Wed、Wadd Ginfo 会员信息 Gno、Gname、Gsex、Gshu Pinfo 提供商信息 Pno、Pname、Ptel、Padd
Mno、Mname、Mbid、Mprice、Mshould、Mamount、Pno、Minfo 商品信息 Mtime
Cinfo 采购信息 Wno、Pno、Mno、Mname、Mamount Dinfo 供货表信息 Dno、Wno、Sno、Mno、Mname、Mamount Einfo 商品销售信息 Eno、Mno、Mname、Mprice、Mamount、Total、Etime
3.2 概念结构设计
具体的全局ER图如下图所示:
10
超市管理数据库设计 学号:141530153 姓名:江浩
供货日期 供货商号 员工信息…
供货商名 供m n 供货 货采电话 商 购n 员 职称 n 地址 查询
商品号 管理 m 学历 商品名 m 员工信息… 籍贯 进价 库
m 身份存售价 管供m n n 证号 调货 商理货管理 品 员 员应有量 n 性别 员 m
现有量更新 姓名 员工信息… 号 供货商号m 管理 号 n 工号 货架号 收
n 银时间 n 商品号 货员结算 m 架超市名 员 打印 商品名 m n 商商品号 品 售价 录入 m 商品名 发现应票 销售时间 1 有有售价 量 量 销售商品 1 属于 数量 (普通)
会员 交易号 总价
总价 单号 会员号 积分 商品号 售价 会员名 商品号 性别 数量
3.3 逻辑结构设计
将实体型转化为关系模型的时候,实体的属性就是关系的属性,实体的码就是
关系的码。对于实体间的联系则有以下不同的情况:
一个m:n联系转换为一个关系模式。与该联系相连的各实体的码以及联系本
身的属性均转换为关系的属性,而关系的码为各实体码的组合。
11
超市管理数据库设计 学号:141530153 姓名:江浩
一个1:n联系可以转换为一个独立的关系模式,也可以与n端对应的关系模式合并。如果转换为一个独立的关系模式,则与该联系相连的各实体的码以及联系本身的属性均转换为关系的属性,而关系的码为n端实体的码。
一个1:1联系可以转换为一个独立的关系模式,也可以与任意一端对应的关系模式合并。三个或三个以上实体间的一个多元联系可以转换为一个关系模式。与该多元联系相连的各实体的码以及联系本身的属性均转换为关系的属性,而关系的码为各实体码的组合。
实体型转换为关系模式如下:
员工(工号,姓名,性别,职称,身份证号,籍贯,学历)
会员(会员号,会员名,性别,积分)
供货商(供货商号,供货商名,电话,地址)
商品(商品号,商品名,进价,售价,应有量,现有量,供货商号,采购日期)
采购单(采购单号,工号,提供商号,商品号,商品名,数量)
供货单(供货单号,工号,货架号,商品号,商品名,数量)
销售单(交易号,商品号,商品名,售价,数量,总价,销售时间)
注释:“工号”:加双下划线的为主码;“供货商号”:加单下划线的为外码;
选出几个例子分析上述由E-R图转换的关系模型的规范化程度:
1、员工(工号,姓名,性别,职称,身份证号,籍贯,学历)
(1)码:工号
(2)主属性:工号
非主属性:姓名,性别,职称,身份证号,籍贯,学历
R,1NF(3)关系中的每一个分量都不可再分,所以
R,3NF(4)非主属性对码既没有传递依赖,也没有部分依赖,所以
R,BCNF主属性对码没有传递依赖和部分依赖,所以
2、采购单(采购单号,工号,提供商号,商品号,商品名,数量)
(1)码:采购单号
(2)主属性:采购单号
非主属性:工号、提供商号、商品号、商品名、数量
R,1NF(3)关系中的每一个分量都不可再分,所以
12
超市管理数据库设计 学号:141530153 姓名:江浩
R,3NF(4)非主属性对码既没有传递依赖,也没有部分依赖,所以
R,BCNF主属性对码没有传递依赖和部分依赖,所以
3.4 物理结构设计与实施
3.4.1建立信息表
为了使信息管理系统的各种数据存储更加具体化,此处特别设定表格说明其字段名、字段类型、字段长度、主/外键、字段值的约束条件和各种字段对应的中文名称。
1(员工信息表设计(Winfo)
员工信息中主码是工号,其他的属性:姓名、性别、职称、身份证号、学历、
籍贯值都由主码决定。
表1 员工信息设计表
中文字段名 字段名 字段类型 长度 主/外键 字段值约束
工号 Wno Char(6) 6 主键 Not null
姓名 Wname Char(20) 20
性别 Wsex Char(5) 5
职称 Wna Char(20) 20
身份证号 Wid Char(18) 18
学历 Wed Char(5) 5
籍贯 Wadd Char(50) 50
2(会员信息表设计(Ginfo)
会员信息存储在会员信息库当中,其中会员号为主码,其他的会员名,性别,消费积分等信息都由主码决定。
表2 会员信息设计表
中文字段名 字段名 字段类型 长度 主/外键 字段值约束
会员号 Gno Char(6) 6 主键 Not null
会员名 Gname Char(20) 20
性别 Gsex Char(5) 5
积分 Gshu Char(10) 10
13
超市管理数据库设计 学号:141530153 姓名:江浩
3. 供货商信息表设计(Pinfo)
供货商信息存储在供货商信息库当中,采购时可以根据主码供货商号来查询供
货商的名称、电话、地址等信息。
表3 供货商信息设计表
中文字段名 字段名 字段类型 长度 主/外键 字段值约束
供货商号 Pno Char(6) 6 主键 Not null
供货商名 Pname Char(20) 20
电话 Ptel Char(11) 11
地址 Padd Char(50) 50
4(商品信息表设计(Minfo)
商品主要包括商品号、商品名、进价、售价、应有量、现有量、供货商号、入
库日期等信息,其中商品号为主码,供货商号是外码其他信息都可以由主码或外码来
决定。
表4商品信息设计表
中文字段名 字段名 字段类型 长度 主/外键 字段值约束
商品号 Mno Char(6) 6 主键 Not null
商品名 Mname Char(20) 20
进价 Mbid float
售价 Mprince float
应有量 Mshould int
现有量 Mamount int
供货商号 Pno Char(6) 6 外键
入库日期 Mtime Char(20)
5(采购单信息表设计(Cinfo)
供货信息主要有采购单号、工号、提供商号、商品号、商品名、数量等信息。
其中以采购单号为主码,以工号、提供商号、商品号为外码。
表5 采购单信息设计表
中文字段名 字段名 字段类型 长度 主/外键 字段值约束
采购单号 Cno Char(6) 6 主键 Not null
工号 Wno Char(6) 6 外键
提供商号 Pno Char(6) 6 外键
商品号 Mno Char(6) 6 外键
商品名 Mname Char(20) 20
数量 Camount Int
14
超市管理数据库设计 学号:141530153 姓名:江浩
6(供货信息表设计(Dinfo)
供货信息主要有货架号、商品号、商品名、应有量、现有量、售价等信息。其
中货架号为主码,商品号为外码。
表6 供货信息设计表
中文字段名 字段名 字段类型 长度 主/外键 字段值约束
供货单号 Dno Char(6) 6 主键 Not null
工号 Wno Char(6) 6 外键
货架号 Sno Char(6) 6
商品号 Mno Char(6) 6 外键
商品名 Mname Char(20) 20
数量 Damount
7(销售单信息表设计(Einfo)
商品销售信息是由收银员结算商后录入商品销售库的,主要包括交易号、商品
号、商品名、售价、数量、总价、销售时间等信息,交易号为主码,商品号为外码。
表7 销售商品信息设计表
中文字段名 字段名 字段类型 长度 主/外键 字段值约束
交易号 Eno Char(6) 6 主键 Not null
商品号 Mno Char(6) 6 外键
商品名 Mname Char(20) 20
售价 Mprince float
数量 Mamount int
总价 Total float
销售时间 Etime Char(20)
3.4.2创建数据库
利用SQL Sever 2008 创建数据库,根据以上物理设计表创建所需要的数据表,
具体代码如下所示:
//员工信息
create table Winfo
(Wno char(6) primary key, Wname char(20),
Wna char(20),
15
超市管理数据库设计 学号:141530153 姓名:江浩
Wsex char(5),
Wid char(18),
Wed char(5),
Wadd char(50)
);
//会员信息
create table Ginfo (Gno char(6) primary key, Gname char(20), Gsex char(5),
Gshu char(10)
);
//提供商信息
create table Pinfo (Pno char(6) primary key, Pname char(20), Ptel char(11),
Padd char(50)
);
//商品信息
create table Minfo (Mno char(6) primary key, Mname char(20),
Mbid float,
Mprice float,
Mshould int,
Mamount int,
Pno char(6) , Mtime char(20),
16
超市管理数据库设计 学号:141530153 姓名:江浩
foreign key (Pno) references Pinfo(Pno) )
//采购信息
create table Cinfo
(Cno char(6) primary key,
Wno char(6) ,
Pno char(6) ,
Mno char(6) ,
Mname char(20),
Mamount int,
foreign key (Wno) references Winfo(Wno), foreign key (Pno) references Pinfo(Pno), foreign key (Mno) references Minfo(Mno) )
//供货表信息
create table Dinfo
(Dno char(6) primary key,
Wno char(6) ,
Sno char(6) ,
Mno char(6) ,
Mname char(20),
Mamount int,
foreign key (Wno) references Winfo(Wno), foreign key (Mno) references Minfo(Mno) )
//商品销售信息
create table Einfo
(Eno char(6) primary key,
Mno char(6),
17
超市管理数据库设计 学号:141530153 姓名:江浩
Mname char(20),
Mprice float,
Mamount int,
Total float,
Etime char(20),
foreign key (Mno) references Minfo(Mno)
建立的部分数据表部分截图如下所示: 商品信息表设计图:
提供商信息图:
18
超市管理数据库设计 学号:141530153 姓名:江浩
员工信息图:
19
超市管理数据库设计 学号:141530153 姓名:江浩
4 结束语
4.1 收获和体会
首先,在设计实体属性的过程中,出现属性名不一致的现象,在后面的设计的时候总能发现和前面不对照的情况,最后不得不列出所有的实体和其属性,并确定简短明了的属性名,逐步去修改上下文中不一致的属性名。
其次,对E-R图的设计出现了偏差,起初,我设计的E-R图是从整个系统的功能入手,需要什么样的功能,便设计出符合功能的实体,结果实体数据很多,出现了数据冗余现象,过于繁杂,同类实体多次出现的问题,由于我自己隐隐感觉到出现了问题,但是自己不知道从何处开始入手,在老师的帮助下渐渐理解了E-R图的设计要点,将同属一类的实体归结为一个实体,并将以前没有考虑的实体之间的关系也加进去,最后才逐渐明了。
这次课程设计是将课本上所学的理论知识和实际操作相结合的一次实践,很大程度上提高了我的实际操作能力,同时,我也所有感想,当利用课本上的理论知识进行实际操作的时候,会遇到很多实际问题,有很多我们理论之外的实际问题需要考虑,而这往往依赖于设计者的理论和实践的结合能力、操作经验。 4.2 总结与展望
本设计对超市管理系统进行了简单的模拟,主要是通过对其主要功能进行设计、模拟,并建立E-R图说明不同实体之间发生的关系。另外,不同职位的员工登陆自己的账户之后可以实现不同的操作,大家各司其职,共同协作,其中管理员拥有所有的权利,登陆个人账户之后,可以通过查询信息、校对信息来判断采购员、供货员、收银员等员工的工作情况,对其工作进行监督。
然而,实践是检验真理的标准,不论什么设计都不能脱离了实际操作,本次对于超市信息管理系统的设计,就有实际问题没有考虑,例如,在实际中可能存在两个或者三个收银台对同一数据进行操作,这样可能产生操作冲突,即事物的并发操作引
20
超市管理数据库设计 学号:141530153 姓名:江浩
起的不一致性,在并发操作下,不同事物对同一数据的操作序列的调度是随即的,可能会引起事物修改的数据丢失,这种并发控制导致数据库不一致性可能出现三种情况:丢失数据、不可重复度和读脏数据。
丢失数据,即当两个收银台读入同一数据并将其修改,结果2号收银台提交的结果修改了1号收银台修改的数据,导致1号收银台的数据修改丢失;读脏数据,如果1号收银台结算了商品之后,2号收银台从数据库读取了数据,用读取的数据执行别的事物,1号收银台的顾客将货物退回,1号收银台从新修改数据,那么2号收银台读取的数据就和数据库的数据不一致,称作是无效数据,这种现象就是2号收银台读取了脏数据。
对于以上这些冲突现象,可以采取封锁的方法来解决,在执行事务之前可以用不同的办法对执行事务需要的数据进行加锁,在解锁之前,其他事务不能更新加锁的数据对象。
还有没有考虑的实际问题,例如,商品销售过程中,要考虑部分饮食商品的保质期,利用系统定时检查哪些商品属于超过保质期的商品,及时将其清理兑换,以免造成出现顾客饮食问题而被投诉等现象。
21
范文五:大数据与传统数据库是互补关系
在全球大数据生态圈中,Hadoop堪称其中最为核心的技术。
由非营利组织管理的Hadoop平台,尽管推行开源模式,但企业并不是拿来就可以用,它需要经过进一步的加工和修缮,由此孕育了多家大数据商业开发公司,如Cloudera、MapR、Hortonworks等。这些公司的商业模式就是开发商业化的Hadoop分发版,并对外销售。
在这些Hadoop分发版开发公司中,Hortonworks刚刚完成IPO,算是最早的一家,目前市值约10亿美元。而要论规模和影响力,则莫过于Cloudera。
Cloudera由分别来自Facebook、谷歌、雅虎和甲骨文的四位创始人于2008年成立。一项数据显示,75%的Hadoop新用户使用的都是Cloudera的分发版。
12月10日,Cloudera正式宣布在中国开始运营,标志着这家已在全球发展了1300多家客户的大数据公司,将业务触角伸向这一潜力市场。Cloudera公司创始人、董事长兼首席战略官Mike Olson亦专程来到中国为新公司站台。
“随着中国交通、电信、金融、医疗等行业领域的飞速发展,越来越多的企业需要快速,甚至是实时的大数据分析。”Mike Olson在接受21世纪经济报道记者专访时表示,大数据在中国企业转型与变革中发挥的作用将愈发显著,而Hadoop作为大数据应用中的主流技术,也将逐渐成为企业应用的核心。
英特尔软件与服务事业部中国区总经理、英特尔亚太研发有限公司总经理何京翔,以及Cloudera公司副总裁、肯睿(上海)软件有限公司总经理凌琦也同时接受了21世纪经济报道记者专访。
50亿美元估值
《21世纪》:Cloudera的四个创始人当中,各自怎么分工,你负责哪些部分,
Mike Olson:我们四位联合创始人分别来自于雅虎、谷歌、Facebook和甲
骨文。我是来自于甲骨文,在此之前创建了Berkeley DB,后来被甲骨文收购了。2008年与另外三位同事一起创建了Cloudera,到现在已经六年半了。现在我的角色是董事长和首席战略官。
另外的三位同事,Jeff Hammerbacher来自Facebook,他现在是我们的首席科学家,他在做很多对人类非常重要的一些事情,比如说基因图谱,利用大数据这样一个工具进行一些重大疾病的研究。Amr Awadallah是我们的CTO,他来自于当年的雅虎,他是最早在雅虎内部使用Hadoop的人之一。Christophe Bisciglia来自于谷歌,尽管他现在已经离开了Cloudera,但是还是在这个生态圈里面,他在Cloudera基础上创建了一些工具和应用,利用大数据这个平台服务客户。
另外还有一个需要提及的人是Doug Cutting。大家都知道Doug Cutting是Hadoop之父,他在2004年写了Hadoop,到2009年加入Cloudera,现在任职我们的首席架构师。
《21世纪》:能否介绍下Cloudera的最新发展情况,
Mike Olson:目前我们全球拥有800名员工,已经有超过50亿美金的市值,有超过1300家的合作伙伴,他们分布在电信、运营商和金融、制造业等各行各业。
Cloudera的商业模式以软件销售为主,同时会提供专业化的服务和认证培训。这类似于Red Hat。诚然,Hadoop是开源的开放式标准,这避免了客户被某一家厂商锁定的风险,但仅仅开源并不够,开源版本更多的是靠一个社区去推动,而企业级客户需要更稳定、更安全、便于管理的企业级平台。这是企业级用户大多会选择Hadoop商业分发版的原因。
从技术角度来讲,Cloudera 的800名员工有一半以上是开发人员,这也就意味着我们对Hadoop社区和整个技术演进的发展方向有非常大的贡献和影响。
联手英特尔
《21世纪》:Cloudera成立六年半后来到中国,准备怎么开展业务,
Mike Olson:我们的中国公司——肯睿(上海)软件有限公司——已经在9月份注册完成,现在正式对外宣布开始运营。目前的团队主要在上海、北京、广州三个地方。业务模式与在美国的业务一脉相承,主要包括四部分:软件开发、营销;合作伙伴支持;解决方案咨询服务;认证培训。
团队方面,我们一方面是本地化,凌琦是Cloudera公司副总裁和肯睿(上海)软件有限公司总经理,他在英特尔工作了20年。另一方面是与英特尔的合作。英特尔向Cloudera投资了7.4亿美金,持有18%的股份,我们在产品和技术和团队上有广泛的合作。
凌琦:我来谈谈中国这边的情况,第一个方面的工作是把以前英特尔的Hadoop分发版的中国客户,转换到Cloudera平台上来。这些客户主要是在金融领域,包括银行、证券、保险等。在此基础上,我们也发现中国市场对大数据的需求在快速增长,比如说电信业,它积累了大量的数据和客户行为数据,这些信息会有很大价值可以挖掘。
我们还看到智慧城市。中国的智慧城市建设非常热,这里面也是靠数据来支持,比如说交通管理,比如说在商业分布,甚至说对于城市安全的管理都有非常好的应用。
另外,大数据在生命科学方面、医药研究方面以及流行病趋势方面,也会有很多应用。
《21世纪》:Cloudera在中国与英特尔将在哪些方面共享资源,
Mike Olson:我们跟英特尔的沟通当中会发现很多大数据潜在的问题,我们可以通过和英特尔或者与英特尔共享的合作伙伴渠道一起提供一个大数据整体解决方案。我们说到的智慧城市、平安城市都是非常典型的大数据应用场景案例。
何京翔:英特尔在上海的大数据开发团队,与Cloudera在开源上有很多的合作;另一方面,我们在共有客户和新客户方面也会合作,来更好满足客户需求。
我本身在英特尔软件及服务事业部工作,这个部门一个主要的任务是使得软件能够在英特尔平台上跑得最好,所以具体落实到大数据这块,就是怎么样让Hadoop、Spark这些新的软件平台在英特尔平台上得到最好的优化,把我们软硬结合做到最好。
与传统数据挖掘是互补关系
《21世纪》:有很多力量在推动大数据发展,其中比较典型的包括传统IT公司面对大数据的转型,以及新兴的创业公司。你怎么看这两类公司的优劣势,
Mike Olson:像Oracle、IBM、Teradata这些传统的数据库或者数据挖掘厂商,其实他们在自己擅长的部分已经做得非常好、非常成功,有非常成熟的解决方案。随着时间的发展,我们现在已经看到越来越多的应用场景和新技术加入到Hadoop平台。正如多年以前谷歌发表了三篇论文,MapReduce、Bigtable、GFS,三篇论文就是Hadoop的原形。Hadoop也是受到这三篇论文的启发。
我认为这两种模式更多的是优势互补。我们现在看到Cloudera做的大数据平台和传统数据仓库EDW数据平台并不是竞争的关系,因为我们可以给他们提供更多的数据,更多种类的数据,不论是从量、种类还是数据类型都会远远超过过去EDW数据能够处理的范围。有了这些数据,用户还是可以用他们熟悉的数据分
析和建模以及数据挖掘的工具,比如说Teradata,比如说MicroStrategy这样的东西去发掘数据的价值。
也就是说,我们这两个方案完全是互补的关系,我们可以给他提供更多种类的数据,让他们从中挖掘更多的价值给到用户。
这里想强调一下我们跟合作伙伴良好的关系,举几个例子,今年10月份,我们宣布了很多合作,比如说跟Teradata、微软、EMC,以及我们跟Oracle做了一体机,这些都是非常好的样板,会告诉大家我们跟这些传统的关系型数据库、数据挖掘公司并不是竞争的关系,而是良好的合作关系。
在Cloudera过去六年半的历史上,我们已经做到了在大数据领域最大,也是最好的分发版提供商,这也是我们跟合作伙伴持续创新、共同发展、共同成长的一个结果。
大数据平台作为一个新生的产品或者一个业界的发展动态,毕竟现在还是一个早期的阶段,对Cloudera这样的新兴的创业公司来讲,在这方面肯定有优势,船小好掉头,这也是大家容易理解的。
《21世纪》:美国大数据领域的创业非常活跃,有很多融资、并购的案例。目前中国大数据领域的创业也在增多。你对这样的创业公司有什么建议,
Mike Olson:一是对这些新兴的中国的创业的大数据厂商,要尽量让自己聚焦在创建一个行业的解决方案或者是一些应用,或者是一些上传的工具,这样能够更好地利用Cloudera非常稳定的、成熟的大数据平台,提供整体的解决方案给到客户。
中国有很多非常活跃的初创企业,我们非常希望能够和合作伙伴一起,通过合作伙伴整个生态圈的打造,能够更多更好地服务于最终客户。
隐私问题的技术视角
《21世纪》:你怎么理解大数据隐私的问题,目前全球有哪些比较好的解决方案,
Mike Olson:用户隐私是一个非常重要的话题,不论是对客户,还是对我们这样一个产品提供商。我们在这方面已经做了很多工作。前期我们在数据加密和优化方面,和英特尔一起发布了很多产品。这是一方面。接下来更多的挑战是,如何把现有我们平台已经有的功能应用到客户的应用场景里去解决客户的真实问题。
凌琦:第一,我们都理解信息安全、隐私非常重要。同时跟国家的政策、法规以及文化、心理习惯有关系,所以从一个技术公司的角度来说,我们更多的定位自己是提供能够加强信息安全和隐私管理的技术。但是上面所进行的应用开发更多是跟本地的公司在一起做的,而这些公司对本地习惯的了解,文化法规的了解,使他能够开发这些应用,符合本地用户的需求。
第二,我们也认识到隐私其实是个人的事情,如果说这个数据能够直接点到每一个人,把你所有的东西都通过大数据的技术找出来,这是个很可怕的事情,从技术上不是不可能。但是我们有一些技术可以通过隐藏这个人本身的身份,但是把这些数据剥离出来,能够知道整个趋势是什么样的,但是把人本身的身份隐藏起来。
Ghost win10旗舰版http://www.xitongchen.com/

