南宫玉儿__
南宫玉儿__
范文一:数理统计知识小结
数理统计知识小结
------缪晓丹 20114041056
第五章 统计量及其分布
§5.1总体与样本
一、 总体与样本
在一个统计问题中, 把研究对象的全体称为总体, 构成总体的每个成员称为个体。 对于 实际问题,总体中的个体是一些实在的人或物。这样,抛开实际背景,总体就是一堆数,这 堆数中有大有小, 有的出现机会多, 有的出现机会小, 因此用一个概率分布去描述和归纳总 体是合适的,从这个意义上说:
总体就是一个分布,而其数量指标就是服从这个分布的随机变量 。
例 5.1.1考察某厂的产品质量,将其产品分为合格品和不合格品,并以 0记合格品,以 1记不格品,若以 p 表示不合格品率,则各总体可用一个二点分布表示:
不同的 p 反映了总体间的差异。
在有些问题中, 我们对每一研究对象可能要观测两个或更多个指标, 此时可用多维随机 向量及其联合分布来描述总体。这种总体称为多维总体。
若总体中的个体数是有限的, 此总体称为有限总体; 否则称为无限总体。 实际中总体中 的个体数大多是有限的,当个体数充分大时,将有限总体看作无限总体是一种合理抽象。
二、样本与简单随机样本 1、样本
为了了解总体的分布,从总体中随机地抽取 n 个个体,记其指标值为 n x x x , , , 21 , 则 n x x x , , , 21 称为总体的一个样本, n 称为样本容量或简称为样本量, 样本中的个体称为 样品。当 30 n 时,称 n x x x , , , 21 为大样本,否则为小样本。
首先指出,样本具有所谓的二重性:一方面,由于样本是从总体中随机抽取的,抽取前 无法预知它们的数值, 因此样本是随机变量, 用大写字母 n X X X , , , 21 表示; 另一方面, 样本在抽取以后经观测就有确定的观测值,因此样本又是一组数值,此时用小写字母
n x x x , , , 21 表示。 简单起见, 无论是样本还是其观测值, 本书中均用 n x x x , , , 21 表示,
从上下文我们能加以区别。
每个样本观测值都能测到一个具体的数值,则称该样本为完全样本,若样本观测值没有 具体的数值, 只有一个范围, 则称这样的样本为分组样本。 从而知道分组样本与完全样本相 比在信息上总有损失,但在实际中, 若样本量特别大,用分组样本既简明扼要,又能帮助人 们更好地认识总体。
2、简单随机样本
从总体中抽取样本可有不同的抽法, 为了能由样本对总体作出较可靠的推断就希望样本 能很好地代表总体。这就需要对抽样方法提出一些要求,最常用的有如下两个要求:
1)样本具有随机性:要求每一个个体都有同等机会被选入样本,这便意味着每一样品
i x 与总体 X 有相同的分布。
2)样本要求有独立性:要求每一样品的取值不影响其它样品的取值,这便意味着
n x x x , , , 21 相互独立。
若样本 n x x x , , , 21 是 n 个相互独立的具有同一分布的随机变量,则称该样本为简单随 机样本,简称为样本。
注(1)若总体 X 的分布函数为 F (x ) ,则其样本的联合分布函数为 ) (1i n
i x F =∏
(2)若总体 X 的密度函数为 p (x ) ,则其样本的联合密度为 ) (1
i n
i x p =∏
(3)若总体 X 的分布列为 ) (i x p ,则其样本的联合分布列为 ) (1
i n
i x p =∏
(4)对有限总体不放回抽样,若总体中有几个个体,抽取样本容量为 n ,当 n
1. 0≤N
n
) 时,不放回抽样得到的样本可认为是简单随机样本。 例 5.1.5 设有一批产品共 N 个,需进行抽样检验以了解其不合格品率 p ,现从中抽出 n 个逐一检查它们是否是不合格品,记合格品为 0,不合格品为 1。则总体为一个二点分布:P(X=1)=p , P (X =0)=1-p 。设 1,..., n x x 为该总体的一个样本,采用不放回抽样得到。这时, 第二次抽到不合格品的概率依赖于第一次抽到的是否是不合格品:
11
) 11(12--=
==N Np x x P 1
) 01(12-===N Np
x x P
但当 N 很大时,上述两个概率近似都等于 p ,所以当 N 很大,而 n 不大时,不放回抽样得 到的样本可近似看成简单随机样本。
§5.2样本数据的整理与显示
一、经验分布函数
1、定义 设 n x x x , , , 21 是取自总体分布函数为 F(x)的样本,若将样本观测值从小到
大进行排列为 ) () 2() 1(, , , n x x x , 则 ) () 2() 1(n x x x ≤≤为有序样本,如下函数
(1)() (1) ()
0, () , , 1, 2, , 11, n k k n x x k
F x x x x k n n x x +<><=-???>? 当 当 当
称为经验分布函数。
2、 经验分布函数的性质
01 对每一个固定的 x , ) (x F n 是事件“ X x ≤”发生的频率,当 n 固定时, ) (x F n 是样
本的函数,是一个随机变量,且 ) () (x F x F P
n ?→?。
02(格里纹科定理)定理 5.2.1:设 n x x x , , , 21 是取自总体分布函数为 F (x ) 的样本,
) (x F n 是经验分布函数,有
1) 0) () (sup lim (==-+∞
<∞-∞→x f="" x="" f="" p="" n="" x="" n="">
注 此定理表明,当 n 相当大时,经验分布函数是总体分布函数的一个良好的近似。
二、频数频率分布表
样本数据的整理是统计研究的基础, 整理数据的最常用方法之一是给出其频数分布表或 频率分布表,其基本步骤是:
1、对样本进行分组:首先确定组数 k ,作为一般性原则,组数通常在 5-20个。对容量 较小的样本, 通常将其分为 5组或 6组, 容量为 100左右的样本可分 7到 10组, 容量在 200左右的样本可分 9~13组,容量为 300左右级以上的样本可分 12到 20组。
2、确定每组组距:每组组距可以相同也可以不同。但实际中常选用长度相同的区间, 以 d 表示组距。
3、确定每组组限。
4、统计样本数据落入每个区间的个数——频数,并列出其频数频率分布表。 具体例子略。
三、 样本数据的图形显示:
常用的样本数据的图形显示主要有直方图和茎叶图,具体例子略。
§5.3统计量及其分布
一、统计量与抽样分布
样本来自总体,含有总体各方面的信息,但这些信息较为分散,有时不能直接利用。为 将这些分散的信息集中起来以反映总体的各种特征, 需要对样本进行加工, 最常用的加工方 法是构造样本的函数,为此:
定义 5.3.1 设 n x x x , , , 21 为取自某总体的样本, 若样本函数 ) , , (1n x x T T =中不含有 任何未知参数,则称 T 为统计量。统计量的分布为抽样分布。
按上述定义:设 n x x x , , , 21 为样本,则 21
1
, i n
i i n
i x x ==∑∑都是统计量,当 2
, σμ未知时,
σ
μ1
1,
x x -等都不是统计量。
注 统计量不依赖于未知参数,但其分布一般是依赖于未知参数的。
二、常用的统计量
1、样本均值、样本方差、样本 k 阶矩及 k 阶中心矩
定义 设 n x x x , , , 21 是来自某总体的样本。称
∑==n
i i x n x 11 为样本均值
∑=-=n
i i x x n S
1
2*) (12
为样本方差 2
**S S = 为样本标准差
∑=--=n
i i x x n S 1
22
) (11 为样本(无偏)方差 2S S = 为样本(无偏)标准差
∑==n i k
i k x n a 11 为样本 k 阶(原点)矩
∑=-=n
i k i k x x n b 1
) (1为样本 k 阶中心矩
注 (1) ∑=--=n i i x x n S 122
) (11=][111
22
∑=--n
i i
x n x n (2)在分组样本场合下:若 i x 为第 i 组的组中值, i f 为该 i 组的个数, k 为组数,则
∑==++=k
i i k k f n n f x f x x 1
11, 其中
∑=--=k i i i x x f n S 122
) (11=][11122
∑=--k i i
i x n x f n 2、次序统计量
定 义 5.3.7设 n x x x , , , 21 是 取 自 总 体 X 的 样 本 , 将 其 从 小 到 大 排 序 得 到
(1)(2)() n x x x ≤≤≤ . 定义 ) (i X :不论 n x x x , , , 21 取怎样的一组观测值, ) (i X 总取 () i x 为
其观测值,称 ) (i X 为第 i 个次序统计量,从而有 ) () 2() 1(n X X X ≤≤.
{}i n
i X X ≤≤=11min , {}i n
i n X X ≤≤=1) (max 分别称为样本的最小、最大次序统计量。
注 样本 n x x x , , , 21 独立同总体分布,但 ) () 2() 1(, , , n X X X 既不独立又不同分布。
三、统计量 X 与 2S 的性质
定理 5.3.1
0) (1
=-∑=n
i i
x x
。
定理 5.3. 2数据观察值与均值的偏差平方和最小,即在形如
∑=-n
i i
c x
1
2) (的函数中,
∑=-n
i i
x x
1
2) (最小,其中 c 为任意给定常数。
定理 5.3.3 设 n x x x , , , 21 是来自某个总体的样本, x 为样本均值。
1) 若总体分布为 ) , (2
σμN ,则 x 的精确分布为 ) 1, (2
σμn
N 。
2) 若总体分布未知或不是正态分布,但 2, σμ==VarX EX , 则 n 较大时的渐近分布为
) 1, (2σμn N , 记为 x . ~) 1
, (2σμn
N 。
定理 5.3.4 设总体 X 具有二阶矩,即 2
, σμ==VarX EX <∞+, n="" x="" x="" x="" ,="" ,="" ,="" 21="" 为从该="" 总体中得到的样本,="" x="" 和="">
S 分别是样本均值与样本方差,则
222, 1
1, σσμ======VarX ES n
VarX n X Var EX X E 。
§5.4三大抽样分布
一、 2χ分布(卡方分布)
1、 定义 5.4.1设 n X X X , , , 21 独立同标准正态分布 N (0,1), 则 ∑==n
i i X 12
2
χ的分布称
为自由度为 n 的 2χ分布,记为 ) (~
22
n χχ.
) (2
n χ的密度函数为:1
122
2
1
() 2()
2
n x n p x x
e
n
--=
Γ, x >0。
1、 性质
1 可加性 若 ) (~), (~22m Y n X χχ且 X 与 Y 独立,则。 ) (~2n m Y X ++χ
证明 略。
2 若 ) (~2n X χ, 则 EX =n , VarX =2n 。
32χ分布的分位数
定义 若 ) (~
22n χχ,对给定的 α, 10<>
αχχα-=≤-1)) ((212n P
的 ) (2
1n αχ-是自由度为 n 的
2χ分布的 α-1分位数。
注
1 要会查 2χ分位数。
2 t —分布、 F —分布仍有相应的分位数定义。
二、 F —分布
1、定义 设 ) (~), (~22n Y m X χχ,且 X 与 Y 独立,则称 //X m
F Y n
=
的分布为自由 度为 (m,n ) 的 F 分布,记为 F~F(m,n ) , m 、 n 分别为分子、分母的自由度。
F (m,n )的密度函数可由商的分布来推导,此处略。
2、性质
(1)
若 ) , (~1
), , (~m n F F
n m F F 则
。 (2)
)
, (1
) , (1m n F n m F αα=
-。
三、 t —分布
1、定义
定义 5.4.3 设随机变量 X 服从 2(0,1),~(), , N Y n X Y χ且 与 独立
则称 t =为自由度为 n 的 t 分布 , 记为 t~t(n ) 。
t (n ) 分布的密度可由商的分布公式来推导 , 此处略 , 但必须注意: 注 (1) t(n) 分布的密度函数为偶函数 , 从而 n >1时 ,Et =0。 (2) t(n) 分布当 n 充分大时 (n ≥ 30), 可用 N (0,1)分布近似。
2、性质
(1) 若 ) , 1(~), (~2
n F t n t t 则 ; (2) 1() (). t n t n αα-=-
四、 Fisher 定理及其推论 1、 Fisher 定理
定理 5.4.1 设 n x x x , , , 21 是来自正态总体 ) , (2σμN 的样本 , 2
s x 和 分别是样本均值与 样本方差,则
(1)) 1, (~2
σμn
N x ;
(2)
∑=--=-n
i i n x x
x s n 1
222
2
) 1(~) (
) 1(σ
σ;
(3)2
s x 与 独立。
注 (1) 在证明 Th5.4.1的过程中有一重要结论即:独立同 N (0,1)分布的随机变量经过正交 变换后得到的仍是独立同 N (0,1)分布的随机变量。
(2) 证明思路 :, , , , , , , , , , 212121n n n z z z y y y x x x ??→???→?正 交 化
标 准 化
而后研究经 过两步变换得到的随机变量之间的关系。
2、三个推论
推论 5.4.1 设 n x x x , , , 21 是来自正态总体 ) , (2σμN 的样本 , 2, s x 为样本均值、样本方 差 , 则 ) 1(~)
(--=
n t s
x n t μ。 分析 按 t —分布定义来证。
推论 5.4.2设 m x x x , , , 21 是来自 ) , (2
11σμN 的样本 , n y y y , , , 21 是来自 ) , (2
22σμN 的样本 , 且两样本相互独立 , 记
21
211221) (11, 1, ) (11, 1∑∑∑∑====--==--==n i i y n i i m i i x m i i y y n s y n y x x m s x m x , 则有 ) 1, 1(~22
22
12
--=
n m F s s F y x
σσ。特别当 22
21
σσ=时 , ). 1, 1(~22--=n m F s s F y
x
分析 据 F —分布的定义结合 Th5.4.1。
推论 5.4.3 在推论 5.4.2的记号下 , 设 2
2
22
1σσσ==, 则有
) 2(~112
) 1() 1() (2221-++-+-+----n m t n
m n m s
n s m y x y
x
μμ。
第六章 参数估计
§6.1点估计的几种方法
一、参数估计问题
这里所指的参数是指如下三类未知参数:
1、 类型已知的分布中所含的未知参数 θ。如二点分布 b(1, p ) 中的概率 p ;正态分布
) , (2σμN 中的 μ和 2σ;
2、 分布中所含的未知参数 θ的函数:如正态分布 ) , (2σμN 的变量 X 不超过给定值 a 的概率 ) (
) (σ
μ
-Φ=≤a a X P 是未知参数 σμ, 的函数;
3、 分布的各种特征数也都是未知参数,如均值 EX ,方差 VarX ,分布中位数等等。 一般场合,常用 θ表示参数,参数 θ所有可能取值的集合称为参数空间,记为 Θ。参数 估计问题就是根据样本对上述各种参数做出估计。
二、概率函数
总体 X 的概率函数 ) , (θx p 是指:当 X 为离散型总体时, ) , (θx p 就是总体的分布列; 当 X 为连续性总体时, ) , (θx p 就是总体的密度函数。
三、参数估计形式
分为点估计与区间估计。
设 n x x x , , , 21 是来自总体的样本, 我们用一个统计量 ) , , (1^
^n x x θθ=的取值作为 θ的 估计值, ^
θ称为 θ的点估计量,简称估计。若给出参数 θ的估计是一个随机区间 ) , (θθ,使 这个区间 ) , (θθ包含参数真值的概率大到一定程度,此时称 ) , (θθ为参数 θ的区间估计。
四、矩法估计
1、替换原理及矩法估计
用样本矩去替换总体矩(矩可以是原点矩也可以是中心矩) ,用样本矩的函数去替换总 体矩的函数,这就是替换原理。
用替换原理得到的未知参数的估计量称为矩法估计。
注 矩法估计适用于总体分布形式未知场合,因此只要知道总体相应的矩即可,而不必 知道其具体分布。
2、概率函数 ) , (θx p 已知时未知参数的矩法估计
设总体的概率函数 ) (1k x p θθ, , ; , Θ∈) , , (1k θθ 是未知参数, n x x x , , , 21 是 总体 X 的样本,若 k
EX 存在,则 j
EX k j , <>
k j EX k j j j , , 2, 1), , , (1 ===θθνμ,
如果 k θθ, , 1 也能够表示成 k μμ, , 1 的函数 k j k j j , , 2, 1), , , (1 ==μμθθ,则可给出
j θ的矩估计量为 k j a a k j j , , 2, 1), , , (??1 ==θθ,其中 k j x n a n i j
i j , , 2, 1, 11
==∑=
设 ) , , (1k g θθη =是 k θθ, , 1 的 函 数 , 则 利 用 替 换 原 理 可 得 到 η的 矩 估 计 量
) ?, , ?(?1k
g θθη =,其中 j θ?是 j θ的矩估计, k j , , 2, 1 =。 例 6.1.2 设总体为指数分布,其密度函数为 0, ) ; (>=-x e x p x λλλ, n x x x , , , 21 为样 本, 0>λ为未知参数,求 λ的矩估计。
解 λ
λ1
), (~=
∴EX Exp X , EX 1=
∴λ, 1?=∴λ
为 λ的矩估计。 注 2
1
), (~λλ=
∴VarX Exp X , VarX 1=
∴λ S
S 1
1?2=
=∴λ
也为 λ的矩估 计。因此矩估计不唯一,此时,尽量采用低阶矩给出未知参数的估计。
例 6.1.3 设总体 ], [~b a U X , n x x x , , , 21 为样本,求 b a , 的矩估计。
解 12
) (, 2],, [~2
a b VarX b a EX b a U X -=+=∴ 由 ??
???
-=
+=12) (22a b VarX b a EX ,得 ???+=-=VarX EX b VarX EX a , 所以 b a ,
的矩估计为 ??a
b ?=??=+??
3、矩估计的步骤
(1)计算总体的各阶矩 j
EX , k j , , 2, 1 =,令
k j EX k j j j , , 2, 1), , , (1 ===θθνμ;
(2)解出 j θ,即 k j k j j , , 2, 1), , , (1 ==μμθθ;
(3)令 k j a a k j j , , 2, 1), , , (??1 ==θθ,其中 k j x n a n i j
i j , , 2, 1, 11
==∑=;
(4)若 ) , , (1k g θθη =,则 ) ?, , ?(?1k g θθη =为 η的矩估计量。 五、最大似然估计
1、最大似然原理
一个试验有若干个可能的结果 A , B , C , ,若在一次试验中结果 A 出现,则一般认 为试验条件对结果 A 出现有利,也即 A 出现的概率最大。
例 6.1.5 产品分为合格品和不合格品两类,用随机变量 X 表示某个产品是否合格,
0=X 表示合格品, 1=X 表示不合格品,从而 ) , 1(~p b X ,其中 p 未知是不合格品率,
现抽取 n 个产品看是否合格,得到样本 n x x x , , , 21 ,这批观测值发生的概率为:
∑
-∑
=-=========-
=-=∏∏n
i i
n
i i
i
i
x n x n
i x x n
i i i n n p p
p p x X p x X x X x X p p L 1
1
)
1()
1()
() , , , () (1
11
2211
当 n x x x , , , 21 已知时, ) (p L 仅是 p 的函数, 既然一次抽样观测到 n x x x , , , 21 , 此时应认 为试验条件对该组样本的出现有利,即该组样本出现的概率最大,从而可求出当 p =?时
) (p L 达到最大,此时把求出的 p =?做为参数 p 的估计就得到 p 的最大似然估计,问题转
化为求 ) (p L 的最大值点。
如果总体为连续型的,求未知参数的最大似然估计仍可转化为求 ) (p L 的最大值点问 题。为此给出似然函数与最大似然估计的定义。
2、似然函数与最大似然估计
定义 6.1.1 设总体 X 的概率函数为 Θ∈θθ), ; (x p 是一个未知参数或几个未知参数组 成的参数向量 , n x x x , , , 21 为来自总体 X 的样本,称样本的联合概率函数为似然函数,用
) , , ; (1n x x L θ表示,简记为 ) (θL ,即
∏===n
i i n x p x x L L 11) , () , , ; () (θθθ
如果统计量 ) , , , (??21n
x x x θθ=满足 ) (max ) ?(θθ
θL L Θ
∈= 则称 ) , , , (??21n
x x x θθ=是 θ的最大似然估计,简记为 MLE 。 由于 x ln 是 x 的单调增函数,因此对数似然函数 ) (ln θL 达到最大与似然函数 ) (θL 达 到最大是等价的。
3、求最大似然估计的两种方法 (1)似然方程法
当 ) (θL 是可微函数时, ) (θL 的极大值点一定是驻点, 从而求最大似然估计往往借助于 求下列似然方程(组)
0)
(ln =??θ
θL
的解得到,而后利用最大值点的条件验证求出的是最大值点。
(2)定义法
虽然求导函数是求最大似然估计量最常用的方法,但并不是所有场合求导都是有效的。
4、最大似然估计的不变性
性质 如果 θ?是 θ的最大似然估计, 则对任一函数 ) (θg , ) ?(θg 是 ) (θg 的最大似然估计。
注 上述性质称为最大似然估计的不变性,从而使求复杂结构的参数的最大似然估计变 得容易,具体应用略。
§6. 2点估计的评价标准
在评价某一个估计好坏时,首先要说明是在哪一个标准下,否则所论好坏则毫无意义。 有一个基本标准是所有的估计都应该满足的, 它是衡量估计是否可行的必要条件, 这就是估 计的相合性。
一、相合性
1、定义
定义 6.2.1 设 Θ∈θ为未知参数, ) , , , (??21n
n n x x x θθ=是 θ的一个估计量, n 是样本 容量,若对任一 0>ε 有
0) ?(lim =>-∞
→εθn n P 即 ) , , , (??21n n n x x x θθ=依概率收敛于 θ,则称 ) , , , (??21n
n n x x x θθ=为 θ的相合估计。 相合性被认为是对估计的一个最基本要求, 如果一个估计量在样本量不断增大时, 它都 不能把被估参数估计到任意指定的精度, 那么这个估计是很值得怀疑的, 通常, 不满足相合 性要求的估计一般不予考虑。
注 证明估计的相合性一般可应用大数定律或直接用定义来证,有时借助于依概率收敛 的性质。
2、相合性的判别定理
定理 6.2.1 设 ) , , , (??21n
n n x x x θθ=是 θ的一个估计量,若 0?lim , ?lim ==∞
→∞→n n n n Var E θθθ 则 ) , , , (??21n
n n x x x θθ=是 θ的相合估计。 定 理 6.2.2 若 nk
n n θθθ?, , ?, ?21 分 别 是 k θθ, , 1 的 相 合 估 计 , ) , , (1k g θθη =是 k θθ, , 1 的连续函数,则 ) ?, , ?(?1nk
n n g θθη =是 ) , , (1k g θθη =的相合估计,
二、无偏性
定义 6.2.2 ) , , , (??21n
x x x θθ=是 θ的一个估计, Θ∈θ, 若对 Θ∈?θ, 有 θθ=?E ,
则称 ) , , , (??21n
x x x θθ=是 θ的无偏估计,否则称为有偏估计。 注 相合性是大样本所具有的性质,而无偏性对一切样本均可以用。
无 偏性可 以改写成 0) ?(=-θθ
E , 这表 明无偏 估计没有 系统偏 差,当 我们使 用 ) , , , (??21n x x x θθ=估计 θ时,由于样本的随机性, ) , , , (??21n
x x x θθ=与 θ总是有偏差 的,这种偏差时而正,时而负,时而大,时而小,无偏性表示,把这些偏差平均起来其值为 零,这就是无偏性的含义。
注 无偏性不具有不变性,即若 ) , , , (??21n
x x x θθ=是 θ的一个无偏估计,一般而言 ) ?(θ
g 不是 ) (θg 的无偏估计,除非 ) ?(θg 是 θ?的线性函数。 注 (1)无偏估计可以不存在; (2)无偏估计可以不唯一; (3)无偏估计未必是一个好 的估计。具体例子略。
三、有效性
参数的无偏估计可以有很多, 如何在无偏估计中进行选择?直观的想法是希望该估计围 绕在参数真值的波动越小越好, 波动大小可用方差来衡量, 因此人们常用无偏估计的方差的 大小作为度量无偏估计优劣的标准,这就是有效性。
定义 6.2.3 设 2
1?, ?θθ是 θ的两个无偏估计,如果对任意的 Θ∈θ,有 ) ?() ?(2
1θθVar Var ≤ 且至少有一个 Θ∈θ使得上述不等式严格成立,则称 1?θ比 2
?θ有效。
四、均方误差
无偏估计是估计的一个优良性质,对无偏估计我们还可以通过其方差进行有效性的比 较,然而不能由此认为:有偏估计一定是不好的估计,在有些场合,有偏估计比无偏估计更 优,这就涉及如何对有偏估计进行评价。 一般而言,在样本量一定时, 评价一个点估计的好
坏使用的度量指标总是点估计值 ) , , , (??21n
x x x θθ=与参数真值 θ的距离的函数,最常用 的函数是距离的平方。 由于具有随机性, 可以对该函数求期望, 这就是下式给出的均方误差
2) ?() ?(θθθ
-=E MSE 简单的推导可得到
2) ?() ?() ?(θθθθ
-+=E Var MSE 若 θθ=?E ,则 ) ?() ?(θθVar MSE =。当 ) , , , (??21n
x x x θθ=不是 θ的无偏估计时,对 均方误差 ) ?(θ
MSE ,不仅要看其方差的大小,还要看偏差大小。在均方误差的标准下,有 些有偏估计优于无偏估计。
范文二:数理统计知识点总结
数理统计 知识点归纳: 第二章
统计量和样本矩
经验分布函数
性质
充分统计量 完备统计量
因子分解定理
例题 2.3解
连续型
完备统计量 解题步骤:
(1)定分布,知密度函数(2)求E (3)令分布E=0(4)推g(x)=0(5)知g (x )为完备统计量
指数型分布族的完备统计量的求法
抽样分布(正态总体样本均值和方差的分布)
非正态总体的样本均值分布
次序统计量 (是充分统计量)
第三章 参数估计 无偏估计
均方误差准则
相合估计
点估计量的求法(1)矩估计法(2)最大似然估计法
矩估计法的理论依据 样本矩是相应总体矩的相合估计,即样本矩依概率收敛于相应的总体矩
Ex =?xd F (x )=?xf (x )dx
Ex 2=?x 2d F (
x )=?x 2f (x )dx
最大似然估计法
用次序统计量估计参数的方法 样本极差R 来估计总体标准差 中位数 来估计均值 最小方差无偏估计 求法步骤:(1)由分布写出联合分布密度函数L (x ;θ)(2)因式分解,证明是充分完备统计量(3)如果不是,利用最大似然函数来求出再证明其完备统计性(4)进行无偏运算得出无偏性E(θ)=θ
有效估计 信息不等式
有效估计
区间估计
一般步骤:
正态总体数学期望的置信区间
第四章 统计决策和贝叶斯估计
贝叶斯估计方法
后验分布
贝叶斯风险 贝叶斯点估计 贝叶斯估计量
第五章 假设检验
独立性检验
第六章 方差分析 单因素分析
双因素非重复分析
双因素重复分析
第七章
回归分析
范文三:数理统计基础知识
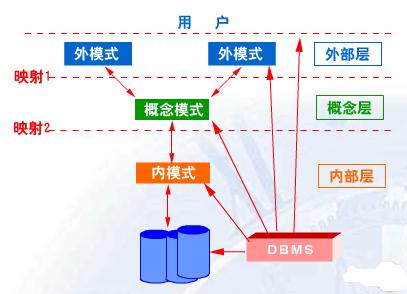
概率论与数理统计简明讲义 数理统计基础
第五章 数理统计基础知识
统计方法可分为统计描述与统计推断。统计描述历史悠久,主要是用少量关键参数刻划总体分布特征。而统计推断发展于上个世纪,相对年轻;它利用观测数据来支持统计假设。下面简要介绍两者的基本概念。
一、 总体与样本
在问题2.13中,我们学会了可用一个连续型随机变量及其密度函数去描述2005p(x)X
年全国19000000新生婴儿的体重。如果完全知道密度函数,就可以计算一个婴儿的体p(x)
重在某个范围的概率以及全国新生婴儿的平均体重和体重的标准差等数字特征,从而更清楚的了解全国新生婴儿的整体状况。但问题是如何求得体重的密度呢, p(x)X
一般地,在概率论中,随机变量的分布通常是假定已知的,概率问题大都是由已知X
的分布去求概率或数字特征等。但实际中怎样才能知道随机变量的分布呢, X
推断描述随机现象的随机变量的分布,正是数理统计要解决的首要问题。为此,我们从所要研究的对象全体中抽取部分进行观测(即抽样调查)以取得信息,进而对整体作出推断。
比如,为了掌握2005年全国19000000新生婴儿的体重的分布,必须先对新生婴儿的体重进行抽样调查。虽然理论上可以进行全面调查,但是实际困难重重,既会耗费大量的人力、物力、财力,也往往由于工作量过大、时间过长等原因影响数据的质量。一项经过科学设计并严格实施的抽样调查结果可能比全面调查更可靠。另一方面,在许多情况下,全面调查根本不可为。例如,对电视机的寿命进行观测,由于是破坏性试验而只能采取抽样调查。
在数理统计学中把研究对象的全体称为总体,而把组成总体的各个单元称为个体。实际问题关心的往往是总体某方面的数量特征,它是一个随机变量。所以统计学认为,总体就是一个随机变量,它的分布称为总体分布。数理统计的基本问题就是推断总体的分布。 F(x)X
从总体中抽取部分个体,称为抽样,即是对进行若干次观测,得到的就是n个随XX
X,?,X机变量,称为样本,其中n为样本容量,样本中的个体称为样品。 1n
为使样本具有充分的代表性,常进行简单随机抽样,即要求:
X(1) 样本有随机性:总体中每个个体入选的机会相等,即每个样品与总体同分布; Xi
X,?,X(2) 样本有独立性:每次抽样的结果不影响其它各次抽样的结果,即相互独立。 1n
简单随机抽样得到的样本称为简单随机样本。从总体中进行有放回抽样,显然是简单随机抽样,得到简单随机样本。从有限总体中进行不放回抽样,虽然不是简单随机抽样,但当
n总体容量N很大而样本容量n较小()时,可近似看作有放回抽样,从而得到近似的,10%N
简单随机样本。除特别声明,以后提到的抽样与样本,均是指简单随机抽样与简单随机样本。
日常生活中也常用抽样调查。要评估一锅汤的味道,没必要把一锅汤喝完;只需将汤搅拌均匀,从中品尝一勺就好。这个例子揭示了抽样方法最重要的信息:
第一,“把汤搅拌均匀”说明抽样的随机性。没有随机性,样本就不能很好地反映总体的情况;把刚加盐的地方舀的汤作为样本,就会推出汤太咸的错误结论;
第二,“品尝一勺”意味样本容量不能太小,也不必太大;少无以知味,多只是浪费;
第三,“无论这锅汤多寡,一勺足矣~”指出:总体容量增大时,样本量不必随之增大。
X,?,X数学上来说,样本相互独立,且与总体同分布,故其联合分布函数是 X1n
n
F(x,?,x),F(x)。 ,nk1,1k
F(x)然而,总体分布函数未知,数理统计的首要问题就是利用样本推断总体的分布。
X,?,Xx,?,x假设从总体中抽取容量为n的样本,得到n个样本观测值。现在该X1n1n
F(x)如何估计总体分布函数呢,
x,?,x直观上看,我们对总体进行n次观测,得到n个观测值,因此可想象存在X1n
xx,?,xx,?,x这样一个离散型随机变量,它只取这n个值,并且概率相等。令是中(k)1n1n第k个小的数(),则这个离散型随机变量的分布函数为: 1,k,n
概率论与数理统计简明讲义 数理统计基础
,0,xx,(1), F(x)kn,xxx,1kn1,,,,,,,nkk()(,1)
,1,xx,n(),
统计上称之为经验分布函数或样本分布函数。下面的定理保证,当n充分大时,样本分布函
F(x)数可作为总体分布函数的良好近似。这就是可以用样本来推断总体的理论依据。 F(x)n
定理3.1:(1)对于任意的x和,有 ; limP(|F(x),F(x)|,,),1,,0n,,,n
(2)。 P(limsup|F(x),F(x)|,0),1n,,,n,,,,,,x
二、统计量及其分布
,为掌握2005年全国19000000新生婴儿的体重的分布,对新生继续考虑问题2.13X
X,?,Xx,?,x婴儿的体重进行抽样调查,得到样本的一组观测值。由此构造的样本1n1n
F(x)分布函数可作为总体分布函数的近似。这是一种估计总体分布的非参数方法,F(x)n
这种方法的适用范围较广,无须知道总体的任何信息;但也有一些缺点:一是需要大的样本
F(x)量,否则近似效果不佳;二是样本分布函数为不连续的阶梯函数,用来估计(是连续n
函数的)连续型随机变量(婴儿体重)的分布函数,好象也有些差距。而实际上,新生X
22N(,,,),,,婴儿的体重应该可以用正态分布描述,只是其中的两个参数未知;于是X
2,,,对总体(新生婴儿体重)的分布推断问题就简化为对这两个未知参数进行推断了。 X
X,?,X样本是相互独立、且分量与总体同分布的一个n维随机变量。为了对总X1n
X,?,X体的某些特征进行推断,需要考虑各种适用的样本函数,即n维随机变量函X1ng(X,?,X)数,若其中不含任何未知参数,则称为统计量。其分布称为抽样分布。 1n
常用统计量:
n1XX,(1) 样本均值 ; ,in,1i
nn211,,222(2) 样本方差 ; SXXXnX,,,,(),,ii,,nn,,11,,11,,ii
n12样本标准差 ; SXX,,(),in,1,1i
n1kVX,(3) 样本k阶原点矩 ; ,kin,1i
XXXX,min(,,,)(4) 最小次序统计量 , (1)12n
XXXX,max(,,,)最大次序统计量 。 ()12nn
nn111定理5.1:(1),.EXEXEX()()(),,DXDXDX,,()()() ,i,i2nnn,1,i1i
2ESDX()(),(2) 。
2X~N(,,,)定理5.2:设总体,则
2,,XX,,,d~(,)XN(1) 样本均值; ; (2) 。 ,u~N(0,1)t,,,,N(0,1),n,nSn
概率论与数理统计简明讲义 数理统计基础 三、统计描述
由于总体分布较难推断,故实际工作常从统计描述开始。统计描述主要用于定量刻划来自一特定总体的一批数据的数量特征。例如,骨质疏松骨折研究(SOF)想调查绝经后美国白人妇女髋部骨折的危险因素,他们从美国四个大都市的绝经后白人妇女中抽选样本,然后用由这些样本估计到的总体分布参数,诸如位置参数、尺度参数和形状参数,来刻划研究总体。 1(连续变量的统计描述
XXX,,,假设从研究总体中随机抽取n个个体,用来表示。下列描述性统计量可12n
用来估计总体的位置、尺度和形状:
(1)位置参数
位置参数表示总体的位置,描述总体的集中趋势。它们用于确定样本的期望值,或一个观测值的平均位置。最常用的位置参数是样本均值。它的优点在于概念直观,不过对异常观测值十分敏感。因此它常和中位数等稳健位置参数一起使用。将观测值按升序排列,如果样本含量n是奇数,中位数定义为排序后的中间观测值;如果n是偶数,中位数定义为排序后两个中间观测值的平均。其它稳健位置参数还有截尾均值、众数和更一般的M-估计量[5]。 (2)尺度参数
尺度参数表示观测数据的变异性或离散程度。大多尺度参数基於观测值离开中心(即位置参数)的平均距离。最常用的尺度参数是样本标准差。如同样本均值,标准差对异常值也很敏感。因此它常与绝对离差中位数(即观测值与中心的绝对离差的中位数)等稳健尺度参数一起使用。其它稳健尺度参数包括全距、四分位距、以及两个基於M-估计量的稳健尺度参
,数:双平方A-估计和Huber 估计[5,6]。
(3)形状参数
形状参数描述观测数据的整个分布形状。偏度和峰度是最有用的形状参数,它们表明观测数据与正态分布的相似程度或差别。偏度描述分布的对称性,是一个有符号的量。如果样
m3mb,m本的二阶和三阶中心矩分别是和,那么偏度系数定义为 ,其中r阶中心矩 3123/2m2
n1rmXX,,()b。为正值表示分布向右偏或长尾,负值表示分布向左偏或负偏倚,,ri1ni,1
m4b,b接近于零意味着近似对称分布。峰度描述分布的峰值高低。峰度系数常定义为 。222m2值大意味着数据中心附近有一个高峰,值小表示峰较为平坦。
骨质疏松研究中统计描述实例
第三期美国营养卫生研究(NHANS)从全美国人群中随机选取14646个成年人[7],其中20-29岁年龄段的非西班牙裔白人男性382人、女性409人,我们以他们的股骨颈(femoral neck)222骨密度(g/cm)峰值为例进行统计描述。样本均值男性是0.934 g/cm,女性是0.858 g/cm,22标准差分别为0.137 g/cm和0.120 g/cm。这表明,非西班牙裔白人男性的骨密度峰值平均th 来说高过女性。其它的描述性统计量包括25%分位数(the 25percentile)(即第一四分位数,th 或下四分位数) 、50%分位数(the 50percentile)(即第二四分位数,或中位数) 、以及75%分th 2位数(the 75percentile)(即第三四分位数,或上四分位数) ,男性分别为0.836 g/cm, 0.929 22222g/cm, 和1.029 g/cm,女性分别为 0.774 g/cm, 0.845 g/cm 和0.944 g/cm。上、下四分位22数的差即为四分位距,男性是0.193 g/cm ,女性是0.170 g/cm。
箱形图
箱形图被认为是概括连续型变量描述性统计量的一种很好的工具,尤其是多个箱形图放置一起便于比较[8,9]。最醒目的视觉特征在於由上、下两个四分位数构成的箱子,它显示一半观测值的大小及中位数的位置(箱子中间的线段)。箱形图同时标明极端值。它不仅给出数据的集中位置和离中趋势,而且包括偏倚程度。图5.1是第三期美国营养卫生研究中20-29岁年龄段的非西班牙裔白人男性和女性股骨颈骨密度的箱形图。另一个用于骨质疏松研究的例子请参见Jowitt等人的文章[10]。JMP软件中的菱形图很像箱形图。
概率论与数理统计简明讲义 数理统计基础
)2
++
++
Femoral Neck BMD (g/cm
0.60.70.80.91.01.11.20.60.70.80.91.01.11.2
MenWomen
图5.1美国NHANSE研究中20-29岁年龄段的非西班牙裔白人男性和女性股骨颈骨密度的箱形图。
由上至下的五条水平线分别对应他们的95%, 75%, 50%(即中位数), 25%和 5%分位数;“+”对应股
骨颈BMD的均值。箱子的高度等於四分位距 (IQD) 。
2(分类数据的统计描述
连续变量用位置、尺度和形状等参数来描述,而分类数据则用频数分布表现。通常分类变量的值不可比,即是说这些值没有顺序。而在某些特殊情况下,分类值可以排序,比如脊椎骨折的严重程度[11]。在一项对中国妇女脊椎骨折危险因素的调查研究中,从北京四个主要城区随机选取50岁以上的绝经后妇女400人[11]。根据受教育程度将她们分成四组:(1) 没有受过教育;(2) 接受教育1至6年;(3) 受教育7至12年;(4) 受教育12年以上。这样我们可用“教育” 这个分类变量来表示她们的受教育情况:对上述四组,它分别取0,1,2,3这四个值;它的频数分布是44.7%, 34.5%, 14.8%和6.0%。
分类数据的一个特例是二分类数据(binary data) ,它常用感兴趣事件的概率来刻划。这个概率可由样本中此事件发生个体所占的比重来估计,表示为p。例如,一个妇女是否患有骨质疏松症就是二分类结果。骨质疏松症的罹患率(prevalence)定义为人群中妇女患有骨质疏松症的比重。按照世界卫生组织(WHO)的标准,骨密度低于年青人参考值2.5个标准差(2.5SD) 的妇女就被诊断为骨质疏松症。用NHANSE[12]作为例子,美国50岁以上的非西班牙裔白人妇女中约有20%估计患有骨质疏松症,此估计的标准误(standard error) 是ppn1,0.2010.201880,==1%。 ,,,,
图5.2 低BMD 的部位频数分布饼图。饼图将 SOF 病人按患骨质疏松症的部位数不同
分为九类,每一类的面积代表相应的百分比。模型 1 基於 WHO 标准;模型 2 以SOF
中65 岁病人为参照;模型 3 利用骨折危险性进行分类。详情请见陆[13]。
概率论与数理统计简明讲义 数理统计基础
分类数据多用条形图(bar chart)表现,图中标明总体中各类所占的百分比。我们也可用饼图(pie chart) 来描述各类在总体中的比重。图5.2是饼图在骨质疏松骨折研究(SOF)中的一个应用实例[13],它给出了世界卫生组织标准下美国非西班牙裔老年白人妇女在脊椎(AP spine), 整个髋部(total hip), 股骨颈(femoral neck), Ward’s triangle(Ward三角区) , 转子(trochanteric), 前臂近端和远端(distal and proximal forearm), 以及跟骨(calcaneal) 等部位患有骨质疏松症的百分比。
第六章 参数估计
一、参数的点估计
在很多统计问题中,总体的分布形式往往是已知的。譬如,由经验可知,大量新生X
22N(,,,),,,婴儿的体重服从正态分布,未知参数是;问题是根据来自总体的样XX
2X,?,X,,,本估计。 1n
X,?,X设样本来自总体是总体的分布中的未知参数,我们用某个统计量XX,,1n
??来估计,称为的估计量。问题是如何寻找的估计, ,,,(X,?,X),,,1n
1. 矩法估计
1900年英国统计学家K Pearson提出,用样本均值(或样本方差)代替总体均值(或总体方差),从而得到未知参数的估计。矩法估计的理论基础是大数定律,后面会进一步讨论。
问题6.1 我们想研究某型号的汽车每5升汽油的行驶里程数,对该型号的20辆汽车记录其每5升汽油的行驶里程(公里),观测数据如下:
29.8 27.6 28.3 27.9 30.1 28.7 29.9 28.0 27.9 28.7
28.4 27.2 29.5 28.5 28.0 30.0 29.1 29.8 29.6 26.9
现在,你可以有什么结论或看法,
某型号的汽车每5升汽油的行驶里程数对于每部汽车来说可能不一样,设为随机变量,这就是我们要研究的总体。首先要注意看这20个样品是否为简单随机样本,如果不是,X
那可能就得不到什么有意义的结论。即使是简单随机样本,因为只有20个样品(属于小样本),也不好贸然估计总体的分布。不过,我们可以利用这些数据推断总体的数字特征。X
按照Pearson的想法,马上得到总体数学期望E(X)D(X)和方差的矩估计分别为
2??E(X),XD(X),S和
2相应的估计值分别是,。 s,0.9185x,28.695
由上面的问题可以看到,矩估计法简便;估计总体均值和总体方差时不必知道总体的分布,这是矩估计法的优点。但是矩估计法需要总体的原点矩存在。还有一个缺点是,矩估计法的效率可能没有下面的最大似然估计法高。
2(最大似然估计法
问题6.2 某同学与一位猎人一起去打猎。一只野兔从前方窜过,一声枪响,野兔应声倒下,试问是谁打中的,
由于只发一枪便打中,而猎人命中的概率显然要大于该同学,故一般会猜测是猎人命中。
在已知结果的情况下,应该寻找使得这个结果出现的可能性最大的那个值作为 的,,估计值。这就是最大似然估计法的思想。这个思想由德国数学家Gauss于1821年首先提出,英国统计学家Fisher于1922年重新发现并作进一步研究。
xxx,,,一般地,我们得到含未知参数θ的总体的一组样本观测值。对离散型随X12n
n机变量总体而言,出现这组观测值的概率(称其为似然函数)是;XLPXx()(;),,,,,ii,1in
fx(;),而对密度为的连续型随机变量总体,我们定义似然函数为。XLfx()(;),,,,ii,1
xxx,,,L(),显然,似然函数值的大小意味着该样本观测值出现的可能性的大小。在得12n
概率论与数理统计简明讲义 数理统计基础
xxx,,,到这组样本观测值的情况下,应选择使似然函数达到最大值的那个值作L(),,12n
为 的估计值(称为最大似然估计)。这种求未知参数点估计的方法称为最大似然估计法。 ,
求参数θ的最大似然估计值,就是求似然函数的最大值点。在可导时可以L(),ln()L,
dLln(),通过求解似然方程: 得到。 ,0d,
3(衡量点估计量好坏的标准
在具体介绍估计量的评价标准之前,我们需要明白:一个估计量的好坏,不能仅仅依据一次试验的结果,而必须由多次试验结果来衡量。因为估计量是随机变量,由不同的观测结果,就会得到不同的参数估计值,所以,一个好的估计,应在多次重复试验中体现其优良性。
对于可取不同值的估计量,一个自然的要求是估计量没有系统偏差,只有随机误差,即
。我们称这样的估计为(参数θ的)无偏估计。 E(),,,
2对任意总体而言,样本均值都是总体均值的无偏估计,样本方差都是XEX()SX
总体方差的无偏估计。 DX()
通常无偏估计不唯一,当然应选方差(即对θ的偏离程度)较小者为好。称未知参数θ
,,的无偏估计比有效,如果。 DD()(),,,1212
DX()X时,总体均值的无偏估计比X有效,因为。 如,n,2DXDX()(),,11n
我们不仅希望一个估计量是无偏的,并且具有较小的方差,还希望当样本量够大时,估
??计量能充分接近未知参数的真值。称为的相合(或一致)估计,如果依概率收敛于,,,,,
?即对,有 。 limP(|,,,|,,),1,,,0n,,,
2由大数定律易知,样本均值XEX()是总体均值的相合估计;样本方差是总体方差SDX()的相合估计。更一般地,大数定律可以保证矩法估计都是相合估计。这就是为什么矩估计法能作为寻求未知参数估计的一种常规方法。
问题6X~U[0,,].3 设总体,现从该总体中抽取容量为10的样本,样本值为
0.5, 1.3, 0.6, 1.7, 2.2, 1.2, 0.8, 1.5, 2.0, 1.6
试问应该如何估计未知参数, ,
E(X),,2我们可以利用矩法和最大似然估计法求参数的估计。先求矩估计。因为 ,
X,,2所以有矩法方程:。
?,,2X解之得θ的矩估计为 ,相应的矩估计值为 。 2x,2.681
x,?,x再求最大似然估计。设样本观测值为,则似然函数为 1n
n11,L(),I,I,(0,x,,)(0,x,,) ni(n),,i,1
Ix,max{x,?,x}0,,,xL(,),0其中,为示性函数。当时,;而(0,x,,)(n)1n(n)(n)
,,xL(,)当时,为的严格单调递减正函数,故的最大似然估计值为,,(n)
??,最大似然估计是。 ,,x,2.2,,X(n)(n)
我们看到,的矩法估计和最大似然估计不一样,那么哪个比较好呢, ,
?E,(),2E(X),2E(X),2,,2,,先看无偏性。因 ,故矩估计是θ的无偏估计。1
?X但是最大似然估计是θ的有偏估计。事实上,不难知道,的密度为 ,,X(n)(n)
n,1n,,,ny,0y,,,p(y) ,0,otherwise,
概率论与数理统计简明讲义 数理统计基础
,1n,1nynn?故 。 E()ydyntdt,,,,,,,,,,,nn1,,00
n,1?不过,我们可以由此构造θ的无偏估计。令,则易知它是θ的无偏估计。 ,,X2(n)n
n,1??,,2X、谁较有效呢, 现在的一个问题是,作为θ的无偏估计,,,X12(n)n
因为
1,n,1nyn222n,12 ,E(X),y,dy,ntdt,,,(n),,nn,2,00
n222D(X),E(X),E(X),,, nnn()()()2(n,1)(n,2)
2(n,1)12?D(),D(X),,,所以 ; n2()2n(n,2)n
2,4412?D(),4D(X),D(X),,,,,而 , 1nn123n
n,1n,1??,,2X故当时,比有效;相应的估计值为。 ,,Xx,2.42n,112(n)(n)nn
读者或许注意到,就无偏性而言,的矩法估计比最大似然估计好;但是,我们可以由,
n,1??,,2X的最大似然估计构造出比矩法估计更有效的无偏估计。 ,,X,12(n)n
参数的点估计是用样本算出来的一个值去估计未知参数,它仅仅是未知参数的一个近似值;既没有明确估计值的误差范围,也没有揭示该何时拒绝关于总体参数的假设。为此,我们常常利用置信区间、假设检验或两者同时进行统计推断。
二、参数的区间估计
所谓区间估计,是希望给出一个估计区间,让我们能以较大的把握(其程度用概率度量)相信未知参数的真值被含在这个区间。显然这样的估计比点估计更有实用价值。在区间估计理论中,流行的一种观点是置信区间,它是1934年由Neymann提出的。
[,,,]称由两个统计量构造的随机区间为参数的置信水平是的置信区间,如果 1,,,
P(,,,,,),1,,。
,通常取0.05或0.01,分别对应置信水平为95%或99%的置信区间。
2N(,),,,对于正态总体(一般情况下总体标准差未知),如果有一容量为n的样本XXX,,,,那么我们容易求出未知参数的矩法估计和最大似然估计都是样本均值,12n
X;再由定理3.3(2),不难得到总体均值的置信水平为置信区间是,1,,
SS[X,t(n,1),X,t(n,1)]t(n,1),这里是样本标准差,是自S1,,21,,21,,2nn
P(t,t(n,1)),1,,2由度为的分布的分位数(满足,其中服从自n,11/2,,tt1,,2
由度为的分布)。 n,1t
在骨密度测量中的一个95%置信区间例子是最小有意义改变(LSC) 。临床决策中重要的是,要知道不大可能由测量误差引起的观测值改变的最小幅度。令X和X是某个体两次12连续的测量,如果测量值没有改变,则它们之间的差异应该只是由纵向测量误差(也叫精度)
,引起的。假定纵向测量误差服从标准差为的正态分布,那么两次测量值之差的标准误是
z2,。由正态分布理论即知 Pr2XXz,,,,,,这里是标准正态分布,,1,,21212,,
概率论与数理统计简明讲义 数理统计基础
P(U,z),1,,2的分位数(满足,其中服从标准正态分布)。取,=5%,1/2,,U1,,2
zz,=1.96,则在两次测量无差异的条件下,区间(-1.96*1.414,, 10.0520.975,
,,,1.96*1.414)=(-2.8, 2.8)有95%的机会包含两次测量的差值。因此,如果个体两次测量
,观察到的改变值大于2.8(即LSC), 我们就有理由认为改变不是由测量误差引起的。最小有意义变化在基础医学中又被称为 “有生物学意义的变化”[14]。更详细的讨论请参见陆等的文章[15] 。
第七章 假设检验
(如单样本问题中的总体均值) 或两个总体参数与假设检验是对一个总体参数,,,1,的相对值(如两样本问题中总体均值之差,,,)进行概率推断的一种方法。我们首先建122
立原假设(或零假设)和备择假设(一般将信以为真并要证实的假设作为备择假设),然后
t选择一个“好”的检验统计量,再计算p值,即零假设成立下统计量“超过” 观测值的TTobs
,概率。最后根据p值来决定是否拒绝零假设。如果p值小于预先给定的显著性水平,那么我们选择拒绝零假设,从而认为备择假设成立;否则没有充分的理由拒绝零假设(但并不意味要接受它)。最常用的显著性水平是,不过它并没有特别的实际意义。 ,,5%
统计假设检验理论很容易用美国司法制度说明。在美国司法制度中,被告(相当于这里要研究的问题)总是假定无罪的(即零假设),直到有证据(即检验统计量)显示无罪假设可能不成立(即p值),这时我们才推翻被告无罪的假定(即拒绝零假设),而判定他有罪(即接受备择假设)。被告确实清白的条件下反而宣判他有罪(即零假设为真时却拒绝它),我们称犯了第一类错误;犯第一类错误的机会就是p值。另一方面,被告的确有罪的情况下反而裁定他无罪(即零假设不真时却接受它),则称犯了第二类错误;犯第二类错误的机会常记作,而,1,,称作功效,即备择假设成立时拒绝零假设的概率。犯两类错误的概率当然是越小越好,但当样本容量固定时,不可能同时把,都减得很小。在实际问题中,一般总是控制犯第一类,,
,错误的概率。这是因为,如同美国司法制度一样,一般认为第一类错误比第二类错误更重要。这种假设检验问题称为显著性假设检验问题。
,由上面的讨论可知,显著性假设检验的结论与选取的显著性水平有关,因此可能犯
,两类错误;犯第一类错误的概率不超过,但是犯第二类错误的概率,常常就不得而知了。
2N(,),,,,,,对于正态总体(总体标准差未知),如果我们想检验零假设对备择0
X,,0,,,假设,一个合适的检验统计量是,相应的p值为 t,0Sn
tt,其中是的观测值,表示自由度为n-1P(|t|,|t|,,,),2(1,t(|t|)tn,1obsobs0n,1obs
,,,的t分布函数。假设这个p值是2%,则我们在显著性水平为5%时拒绝零假设,而0在显著性水平为1%时没有充分的理由拒绝它。
.1 Gramp等人[16] 用CT技术来比较绝经前、后正常妇女的骨密度值,得到47问题7
位(n) 绝经前正常妇女的骨小梁骨密度(trabecular BMD)的均值(m) 和标准差(s) 分别为11133178 mg/cm和33 mg/cm,而41位(n) 绝经后正常妇女相应的均值(m) 和标准差(s) 则为22233106 mg/cm和30 mg/cm。零假设是绝经前、后正常妇女的骨小梁骨密度值没有差异。给定显著性水平为5%。利用两独立样本的t检验方法,检验统计量观测值为
22,,tmmnsnsnn,,,,,,,112 ,,,,,,,,12112212,,
221781064633403086,,,,==2.2756。 ,,,,
由此可知,在零假设成立时实际观察到此类值的机会(即p值)只有
,小于显著性水平P(|t|,|2.28|,,,),2(1,t(|2.28|),2(1,0.9887),2.3%1286
5%。这样,我们有理由拒绝零假设,从而认为绝经前、后正常妇女的骨小梁骨密度的差异有统计学意义。
概率论与数理统计简明讲义 数理统计基础
值得注意的是,统计推断的经典方法,如上例中的学生t检验(Student’s t tests),依赖于
数据服从正态分布且相互独立等前提假定。如果数据含有异常值或非正态(如双峰或严重偏
倚),那么必须使用稳健或非参数方法进行可靠的统计推断[17,18]。另外需要一些特殊的统
计方法处理不独立的样本数据,比如从同一个体得到的多个脊椎或重复的测量值[19] 。
参考文献
[1] Paulos, J.A. (柳柏濂译). 数盲—数学无知者眼中的迷惘世界。上海教育出版社, 上海, 2006.
[2] 何书元. 概率论与数理统计。高等教育出版社, 北京, 2006.
[3] 茆诗松, 程依明, 濮晓龙. 概率论与数理统计教程。高等教育出版社, 北京, 2004.
[4] 吴赣昌. 概率论与数理统计 (理工类)。中国人民大学出版社, 北京, 2006.
[5] Wilcox, R. R. Introduction to Robust Estimation and Hypothesis Testing (Academic Press, San
Diego, 1997).
[6] Yohai, V. J. & Zamar, R. (Department of Statistics, University of Washington, Seattle, 1986).
[7] Looker, A. et al. Updated data on proximal femur bone mineral levels of US adults. Osteoporosis
International 8, 468-89 (1998).
[8] Tukey, J. W. Data-based graphics: visual display in the decades to come. Statistical Science 5
(1990).
[9] 谭铭, 许宗利. 医学研究中的数据描述。 现代医学统计学 (方积乾, 陆盈主编) 210-218 (人民
卫生出版社, 北京, 2001).
[10] Jowitt, N., MacFarlane, T., Devlin, H., Klemetti, E. & Horner, K. The reproducibility of the
mandibular cortical index. Dentomaxillofacial Radiology 28, 141-144 (1999).
[11] Xu, L. et al. Vertebral fractures in Beijing, China: the Beijing Osteoporosis Project. Journal of
Bone and Mineral Research 15, 2019-2025 (2000).
[12] Looker, A. C. et al. Prevalence of low femoral bone density in older U.S. adults from NHANES III
[see comments]. Journal of Bone and Mineral Research 12, 1761-8 (1997).
[13] Lu, Y. et al. Classification of Osteoporosis Based on Bone Mineral Densities. Journal of Bone and
Mineral Research 16, 901-910 (2001).
[14] Strike, P. W. Statistical Methods in Laboratory Medicine (Butterworth-Heinemann Ltd., Oxford,
1991).
[15] 陆盈, 赵守军, 颜杰. 统计学方法在放射医学研究的质量控制, 质量保障和质量改进中的应
用。现代医学统计学 (方积乾, 陆盈主编) 62-96 (人民卫生出版社, 北京, 2001).
[16] Grampp, S. et al. Comparisons of non-invasive bone mineral measurements in assessing
age-related loss, fracture discrimination, and diagnostic classification. Journal of Bone and
Mineral Research 12, 697-711 (1997).
[17] Conover, W. J. Practical Nonparametric Statistics (John Wiley & Sons, Inc., New York, 1980). [18] Snedecor, G. W. & Cochran, W. G. Statistical Methods (Iowa State university Press, Ames, IA,
1980).
[19] Heidelberger, P. & Welch, P. D. A spectral method for confidence interval generation and
run-length control in simulations. Communications of the ACM 24, 233-245 (1981).
范文四:数理统计有关基础知识
第4章 数理统计的基础知识
数理统计与概率论是两个有密切联系的学科, 它们都以随机现象的统计规律为研究对象. 但在研究问题的方法上有很大区别:
概率论 —— 已知随机变量服从某分布, 寻求分布的性质、数字特征、及其应用;
数理统计 —— 通过对实验数据的统计分析, 寻找所服从的分布和数字特征, 从而推断整体的规律性. 数理统计的核心问题——由样本推断总体
从本章开始,我们将讨论另一主题:数理统计。
数理统计是研究统计工作的一般原理和方法的科学,它主要阐述搜集、整理、分析统计数据,并据以对研究对象进行统计推断的理论和方法,是统计学的核心和基础。
本章将介绍数理统计的基本概念:总体、样本、统计量与抽样分布。
由于大量随机现象必然呈现出它的规律性,因而从理论上讲,只要对随机现象进行足够多次观察,被研究的随机现象的规律性一定能清楚地呈现出来。但客观上只允许我们对随机现象进行次数不多的观察试验,也就是说, 我们获得的只是局部观察资料。
数理统计就是在概率论的基础上研究怎样以有效的方式收集、整理和分析可获的有限的, 带有随机性的数据资料, 对所考察问题的统计性规律尽可能地作出精确而可靠的推断或预测,为采取一定的决策和行动提供依据和建议.
§4.1 总体与样本
一、 总体与总体分布
1. 总体:具有一定的共同属性的研究对象全体。总体中每个对象或成员称为个体。
研究某批灯泡的质量,该批灯泡寿命的全体就是总体;考察国产 轿车的质量,所有国产轿车每公里耗油量的全体就是总体;某高校学习“高等数学”的全体一年级学生。
个体与总体的关系,即集合中元素与集合之间的关系。统计学中关心的不是每个个体的所有具体特性,而是它的某一项或某几项数量指标。某高校一年级学生“高等数学”的期末考试成绩。
对于选定的数量指标 X (可以是向量)而言,每个个体所取的值是不同的,这一数量指标X 就是一个随机变量(或向量);X 的概率分布就完全描述了总体中我们所关心的这一数量指标的分布情况。数量指标X 的分布就称为总体的分布。
定义4.1 统计学中称随机变量(或向量)X 为总体,并把随机
变量(或向量)X 的分布称为总体分布.
说明
1. 表示总体的X 既可以是随机变量,也可以是随机向量 . 2. 有时个体的特性本身不是直接由数量指标来描述的. 例如 服装厂生产的各式服装,玩具厂生产的儿童玩具,检验部门通常将产品分成若干等级。
3. 总体分布就是设定的表示总体的随机变量X 的分布.
总体的分布一般来说是未知的,统计学的主要任务正是要对总体的未知分布进行推断。
二 样本与样本分布
定义4. 2 称(X 1, X 2, , X n ) 为总体X 的简单随机样本,若X 1, X 2, , X n 是独立同分布的随机变量,且与总体X 同分布,样本中所含分量的个数n 称为该样本的容量.
以下假定所考虑的样本均为简单随机样本,并简称为样本。 样本的双重理解
在未观察具体的抽样结果时,样本(X 1, X 2, , X n ) 视为随机向量. 观察具体的抽样结果后,样本便可理解为所得的一组具体的观察值(x 1, x 2, , x n ), 称为 样本值.
全体样本值组成的集合称为样本空间
, X n ) 的分布函数为 设总体X 的分布函数为F (x ), 则样本(X 1, X 2, F (x 1 ,x 2, , x n ) =∏F (x i ). 称之为样本分布.
i =1n
若总体X 为离散型随机变量,概率分布为p (x ) =P {X =x },x 取遍X 所有
可能值,则样本的概率分布为
p (x 1,x 2, , x n ) =P {X 1=x 1, X 2=x 2, , X n =x n }=∏p (x i ).
i =1n
例41 . 称总体X 为正态总体,如它服从正态分布. 正态总体是统计应用
中最 常见的总体. 现设总体X 服从正态分布N (μ, σ2), 则气样本密度由下式
给出:
n
1x -μ2
-(i ) }f (x i )
2σi =1
1n n
=exp{-2∑(x i -μ) 2}.
2σi =1 f (x 1,x 2, , x n ) = 例4.2 称总体X 为伯努利总体,如它服从以p (0
<1) 为参数的伯努利分布.="">
P {X =1}=p , P {X =0}=1-p .
其样本(X 1, X 2, , X n ) 的概率分布为:
{X =i , X =i , , X =i }=p s n (1-p)n -s n P 1122n n
其中i k (1≤k ≤n ) 取1或0,而s n =i 1+i 2+ +i n , 它恰等于样本中取值为
1的分量之总数. 例4. 3 设总体X 服从参数为λ的泊松分布,(X 1, X 2, , X n ) 为其样本,
则样本的概率分布为:
P {X 1=i 1, X 2=i 2, , X n =i n }=∏P {X =i k }
k =1
=∏
k =1n
n
λi
k
i k !
-λ
=
λs
n
i 1! i 2! i n !
e -n λ.
其中
i k (1≤k ≤n ) 取非负整数,而s n =i 1+i 2+ +i n .
三 统计推断问题简述
借助于总体X 的一个样本(X 1, X 2, , X n ) ,对总体X 的未知分布进行
推断,我们把这类问题统称为统计推断问题.
为利用样本对未知的总体分布进行推断,我们需要借助样本构造
样本的适当的函数,正是利用这些函数所反映的总体分布的信息来对
总体分布所属的类型,或总体分布中所含的未知参数作出统计推断.
§4.2 统计量
一、统计量的定义
定义3 设(X 1, X 2, , X n ) 为总体X 的一个样本,称此样本的任一不含 4.
总体分布未知参数的函数为该样本的统计量.
例4. 4 设总体X 服从正态分布,EX =5, DX =σ2, σ2未知.(X 1, X 2, , X n ) 为
总体X 的一个样本,令 S
S n =X 1+X 2+ +X n , X =n . n
则S 与X 均为样本(X , X , , X ) 的统计量.
n 12n n (X -5) 但若令 U =,
σ
则U 不是该样本的统计量,因U 的表示式中含有总体分布中的位置参数σ.
二、常用的统计量
设(X , X , , X ) 为总体X 的一个样本.
12n
1. 样本均值
称样本的算术平均值为样本均值,记为X , 即
1
X =(X 1+X 2+ +X n ) .
n
2. 样本方差
样本方差是用来描述样本中诸分量与样本均值的均方差异的,它有
两种定义方式。直观的: 1n 22 S =(X -X ) . 0i
n i =1
2并称S 为样本的未修正样本方差. 0
统计学中更常用另一种定义,即 n 21n 2
S 0=(X i -X ) 2. S =
n -1n -1i =1
并称S 2为样本的修正样本方差.
∑
∑
以后简称修正样本方差为样本方差.
3. 样本标准差
样本标准差S 定义为样本方差的算术平方根,即S =4. 样本原点距
1n
记 A k =∑X i k , k ≥1
n i =1
并称A k 为样本的k 阶原点距. 5. 样本中心距
1n
记 B k =∑(X i -X ) , k ≥1
n i =1
二阶中心矩即为未修正样本方差 并称B k 为样本的k 阶中心距.
一阶原点矩即为样本均值.
上述五种统计量可统称为样本的矩统计量,简称为样本矩. 他们皆可表为样本的显式函数。
6. 顺序统计量
设(X 1, X 2, , X n ) 为总体X 的一个样本. 将样本中的诸分量按由小 到大的次序排列成 X ≤X ≤ ≤X ,
(1)
(2)
(n )
则称(X (1), X (2), , X (n ) ) 为样本的一组顺序统计量,称X (i ) 为样本的第i 个
顺序统计量.
特别地,称X (1)=min(X 1, X 2, , X n ) 与X (1)=max(X 1, X 2, , X n )
分别为样本极小值与样本极大值,并称X (n ) -X (1)为样本的极差.
三、枢轴量
设(X 1, X 2, , X n ) 为总体X 的一个样本,需推断总体分布中某一未知 参数θ,构造一个样本函数
U (X , X , , X ; θ), 服从一个已知分布.
1
2
n
仅含一个未知参数,但其分布却已知的样本函数成为枢轴量。
22
例4. 5 设总体X N (μ, σ), 其中σ已知,μ未知,(X 1, X 2, , X n ) 为00
总体X 的一个样本,令
U =
§4.3 常用的统计分布
统计的目的就是借助从总体X 中随机抽取的样本(X 1, , X n ) ,构造相应的统计量(枢轴量),通过研究它们的分布来对未知的总体分布进行推断. 因此,本节将要补充统计学中经常用到的分布: χ 分布、F分布与 t 分布。
一、分位数
在统计推断中,经常用到统计分布的一类数字特征-分位数,在讲常用的统计分布之前,我们先给出分位数的一般概念和性质,这对于以后查阅常用统计分布表和解决第五章的有关参数的区间估计和假设检验的问题都是非常有用的.
1、上侧分位数定义
定义44. 设随机变量X 的分布函数为F (x ) ,对给定的实(0F α}
即 1-F (F α) =α 或 F (F α) =1-α (4.7)
2
则称F α为随机变量X 的分布的水平α的上侧分位数. 或直接称为分布函数F (x ) 的水平α的上侧分位数.
2、上侧分位数的性质
(1) 若F (x ) 是严格单调递增的, 则 F α=F -1(1-α);(4.8)
(2)若X ~f (x ) , 则?
+∞
F α
f (x ) dx =α;
(4.9)(4.10)(4.11)
(3)若X ~N (0,1), 记水平α的上侧分位数为u α, 则1-Φ0(u α) =α, 即Φ0(u α) =1-α; (4)P {X ≤F 1-α}=α, P {F
1-
α
2
2
对于像标准正态分布那样的对称分布(密度函数为偶函数),统计学中还用到双侧分位数。
3、双侧分位数定义
定义4. 5设X 是对称分布的连续型随机变量,分布函数为F (x ) , 对于给定的实数α(0<><1), 如果正实数t="" α满足="" p="" {x="">T α}=α, (4.12)即F (T α) -F (-T α) =1-α. (4.13)
则称T α为随机变量X 的分布的水平α的双侧分位数,也简称位分位数, 或直接称为分布函数F (x ) 的水平α的分位数.
4、双侧分位数的性质
由X 分布的对称性容易知道以下关系式成立:(1)F (T α) =1-
α
2
,
或
P {X >T α}=1-F (T α) =(2)(3)
T α=F α
α
2
(4.14)(4.15)(4.16)
F α=-F 1-α
5、上侧分位数和双侧分位数的例题
例4.6设X N (0,1),求水平α=0.05的上侧分位数和双侧分位数.
解:由于 P {X >u 0.05}=0.05, 所以 Φ0(u 0.05) =1-0.05=0.95,
查表可得 u 0.05=1.645.
而水平0.05的双侧分位数为u ,它满足Φ(u ) =1-0.025=0.975,
0.025
0.025
查表得 u 0.025=1.96.
2
χ二、 分布 2χ1、 分布的定义
定义
4. 6如果随机变量X 的密度函数为
n 1-1-x 1
f (x ) =n x 2e 2(4.18)
n 22Γ()
2
其中Γ(a ) =?x a -1e -x dx (a >0) 是Γ函数, 称X 服从
n 个自由度的χ2分布,记作X ~χ2(n ) .
对定义4.6的几点说明
+∞
1
(1)Γ() =Γ(a ) =(a -1)!(当a 是正整数时)
2
2n +12n -12n -31Γ() = Γ()(当n =1, 2, 时)
2222
1
(2)χ2(2)是λ=的指数分布.
2
(3)χ2(n ) (n ≥3) 的密度函数为单峰曲线,从原点开始递增,在
x =n -2处取得最大值,然后递减, 渐进于x 轴,关于x =n -2不对称. (4)χ2(1)的密度函数在x =0处取无穷大,以y 轴为 垂直渐进线
2、χ2分布的典型模式
题4.1设X 1, X 2, , X n 是n 个相互独立的随机变量, 且 命
2222X ~N (0,1), i =1,2, , n , 则X =X +X + X 服从 χ(n ) 分布. i 12n
2
3、χ分布关于自由度的可加性
命题4.2()若1X ~χ2(m ), Y ~χ2(n ), 且X 与Y 相互独立,则
X +Y ~χ2(m +n ).
(2)若X ~χ2(n ), 则EX =n , DX =2n .
证明设 X 1, X 2, , X m +n 独立、服从标准正态分布.
2
(1)由于X ~χ2(m ) ,根据定义4.6与命题4.1, X 与X 12+X 22+ X m 同分布,Y 与222222X +X + X 同分步,再由X 与Y 独立知,X +Y 与X +X + X m +2m +n 12m +n m +1
同分布,所以X +Y ~χ2(m +n ) .
(2)设X 1,X 2, ,X n 相互独立且均服从标准正态分布,
EX =E ∑X =∑EX =∑DX i =n .
2
i
2i
i =1
i =1
i =1
n
n
n
2222
由X ~χ(n ) 知X 与X +X + X 12n 同分布,
于是
4此外, 由于E [X i ]=3(见习题四(B)的第四题), 便知
D [X i 2]=E [X i 4]-(E [X i 2])2=3-1=2.
再因X 1,X 2, ,X n 相互独立, 即得
DX =D ∑X =∑DX i 2=2n .
2
i
i =1
i =1
n n
上述命题中第一个结论实际上说明χ2分布同正态分布一样具有可加性.
4、χ2分布的计算
由于χ2分布是常用的统计分布,但又难于利用其密度函数χ2(x , n )
进行直接计算,通常也为其制定了统计用表. 附表3中对自由度n ≤45
22
的χ分布给出了水平α的上侧分位数χα(n ) 之值.
当X ~χ2(n ) 时, 由(4.6)与(4.10)两式可以得到
2
P {X >χα(n )}=P {X <χ12-α(n )}="">
22
因为χ(x ; n ) 不是对称函数, 故对χ分布而言, 不存在双侧分位数,
但在以后统计推断中, 将用到等式 2 P ({X <χ2α(n )}?{x="">χα(n )})=α,22 2或P {χ2α(n )}
1-22
1-
2
例如, 设X χ(10),取水平α=0.05, 查表可知
P {X <3.940}=p {x="">18.307}=0.05, P {3.247≤X ≤20.483}=0.95.
当自由度n 充分大(如n >45) 时, χ2分布可近似地看作正态分布, 于是由正态分布的分位数可近似地求得χ2分布的分位数.
三、F 分布
1、F 分布的定义
定义4. 7如果随机变量X 的密度函数为
m 1-1-(m +n ) 1m m m f (x ; m , n ) =()(x ) 2(1+x ) 2
n B (, ) n n
22
1
(4.20)
p -1q -1其中B (p , q ) =x (1-x ) dx (p >0, q >0) 是B(贝塔) 函数, 称X ?0
服从第一自由度为m , 第二自由度为n 的F 分布, 记作X ~F (m , n ) .
对定义4.7的说明
F 分布的密度函数曲线也为单峰曲线,当第一自由度m ≥3时, m -2n 曲线在x *=处达最大值. 显见x *<>
m n +2
小于1处取到. 此外,不难看出,当两个自由度m 与n 都变得越来越
大时,x *接近1,从而函数曲线就在非常接近1的地方达到最高点.
图4.5给出了若干F 分布的密度函数曲线.
2 、F 分布的典型模式
命题4. 3设X χ2(m ), Y χ2(n ), 且X 与Y 相互独立, X
nX
记Z == Y mY
n
则Z 的密度函数为(4.20), 因此Z ~F (m , n ).
由命题4.3不难看出,若X ~F (m , n ) ,则X -1~F (n , m ).
3、F 分布的计算
P ({X 1-2 2 或P {F α(m , n ) 1-2 2 例子:(1)对于较小的α,可以直接由附表4查出 F 分布的上侧分位数. 设X ~F (5,10), 查表4知 P {X >3.33}=0.05, P {X >4.24}=0.025. 又设Y ~F (10,5), 查表4知 P {Y >4.74}=0.05, P {Y >6.62}=0.025. (2)当α接近于1时,可以利用下式求出所需的上侧分位数 1 F α(m , n ) =. (4.21) F 1-α(n , m ) 11 F 0.95(m , n ) =, F 0.975(m , n ) =. F 0.05(n , m ) F 0.025(n , m ) 这样,当 X ~F (5,10)时,查表可知P {X 11=0.05, P {≤X ≤4.24}=0.95. 4.746.62 四、t 分布 1、t 分布的定义 定义4. 8如果随机变量X 的密度函数为 (4.23) +1 x 2-n 2 t (x ; n ) =(1+) , -∞ n 称X 服从自由度为n 的t 分布,记作X ~t (n ) . 对定义4.8的说明 (1)t 分布的密度函数曲线也为单峰曲线,但关于y 轴对称,在 x =0处取到最大值. x 轴为其水平渐近线. 图4.6给出了自由度n =1,5,10, ∞时t 分布的密度函数曲线. (2) 当自由度n 很大时,t 分布也接近于标准正态分布,这是 +11 -x 2 x 2-n 2 因为 lim(1+) =e 2. x →∞n n =∞时的t 分布的密度函数曲线,即为标准正态分布的密度函数 曲线,但比标准正态分布的尾部有更大的概率 . 2、t 分布的典型模式 (0,1), Y χ2(n ), 且X 与Y 相互独立,记 命题4.4设X N 则T 的密度函数为(4.23), 因此T ~t (n ). 由命题4.4不难看出,若X ~F (1,n ) ~t (n ). 3、t 分布的计算 T = 附表5对于一些充分小的α值给出了t 分布的水平α的上侧分位数t α(n ) 之值. 由于t 分布具有对称的密度函数,当α接近1时,可按下式 求出相应的上侧分位数: t α(n ) =-t 1-α(n ). (4.24) 因此,如X t (n ), 由(4.6),(4.10)与上式得: P {X >t α(n )}=P {X <-t α(n="" )}="α." 再由于t="" 分布具有对称的密度函数,具有双侧="" 分位数,由(4.12)="" 与(4.15)知="" p="" {x="">t α(n )}=α. 例如,设X t (8),取水平α=0.05, 查表可知t α(8)=1.860, t α(8)=2.306, 故有 P {X >1.860}=P {X <1.860}=p {x="">2.306}=0.05. 此外,由于自由度n 充分大时,t 分布近似于标准正态分布, 故有 t α(n ) ≈u α, 其中u α为标准正态分布的上侧分位数. §4.4 抽样分布 总体的分布是未知的,或是部分未知的. 对总体的分布进行的统计推断称为非参数统计推断;对总体未知的重要数字特征(如总体数学期望、总体方差)或总体分布中所含的未知参数进行统计推断. 这类问题称为参数统计推断. 在参数统计推断问题中,经常需要利用总体的样本构造出合适的统计量(或枢轴量),并使其服从或渐近服从已知的确定分布。 统计学中泛称统计量(或枢轴量)的分布为抽样分布. 讨论抽样分布的途径有两个:一是精确地求出抽样分布,并称相应地统计推断为小样本统计推断;另一种方式是让样本容量趋于无穷,并求出抽样分布地极限分布;然后,在样本容量充分大时,可利用该极限分布作为抽样分布地近似分布,再对未知参数进行统计推断,因此称相应的统计推断为大样本统计推断. 本节重点讲述正态总体的抽样分布。 一、正态总体的抽样分布 上节讲述的三种常用的统计分布(χ2分布、F 分布和t 分布)为讨论 正态总体的抽样分布作了必要的准备. 不过,在一般地讨论正态分布的抽样分布以前,我们还需要正态总体抽样分布的一个基础性定理,那就是涉 及正态总体样本均值与样本方差的抽样分布的定理. 定理4.1设总体X ~N (μ, σ2), (X 1, X 1, , X n ) 是其容量为n 的一个 2样本,与S 分别为此样本的样本均值与样本方差,则有 (1)(2) (3) N (μ, n -1 σ2 n ); σ2 S 2 χ2(n -1); 与S 2相互独立. 证明结论(1)可以由一个重要性质(一组相互独立服从正 态分布的随机变量的非零线性组合仍然服从正态分布)得到. 讨论 (2)与(3)的严格证明需要用到关于多重积分的变量替换公式,此外还要利用正交矩阵的一些性质,数学推导的技巧性很强,故 此处省略,有兴趣的同学可以参考附录4.2. 有了上述关于正态总体的样本均值与样本方差的抽样分布的基础性定理,再结合上一节中的常用统计分布,就可以容易地构造单正态总体与双正态总体中样本的一些统计量(枢轴量)并使之服从确定的已知分布。 1、 单正态总体的抽样分布 定理4. 2 设(X 1, X 2, , X n ) 为正态总体X ~N (μ, σ2) 的样本, 2与 S 分别为该样本的样本均值与样本方差,则 (1)U = N (0,1); n -1 (2)2S 2 χ2(n -1); σ t (n -1). (3)T = 证明结论(1)是定理4.1(1)的直接推论. 结论(2)已经由定 理4.1的(2)给出,再因为 T = , n -12 且由定理4.1知U 与2S 相互独立,故由本定理的结论(1)、(2) σ 与命题4.4知T ~t (n -1) . 2、 双正态总体的抽样分布 在统计学的应用中,有时要比较两个正态总体的参数,下述定理为比较两个正态总体的参数提供了合适的统计量(或枢轴量) 。 2 定理4.3 设X ~N (μ1, σ12) 与Y ~N (μ2, σ2) 是两个相互独立的正态总体. 又设(X 1, X 2, , X n 1) 为总体X 的容量为n 1的样本,与S 12分 别为该样本的样本均值与样本方差. 再设(Y 1, Y 2, , Y n 2) 为总体Y 的容量 为n 的样本,与S 2分别为此样本的样本均值与样本方差. 记S 2是 2 2 22 S 1与 S 2的加权平均: 则有 S 2= n 1-1n 2-12 S 12+S 2, n 1+n 2-2n 1+n 2-2 (1)U = N (0,1); σ22S 12 (2)F =() 2 F (n 1-1, n 2-1); σ1S 2 2 (3)当σ12=σ2=σ2时, T = t (n 1+n 2-2). 二、一般总体抽样分布的极限分布 本小结将取消定理4.2中总体服从正态分布的条件,这时将不能 精确地导出样本函数U 与T 的分布函数的显式。于是,考虑当样本容量n 趋于无穷时,相应的分布函数是否存在极限分布?为此,首先需引入概率论中有别于依概率收敛的另一种收敛性概念,即依分布收敛的概念. 设F n (x ) 为随机变量X n 的分布函数,F(x ) 为随机变量X 的 分布函数,记C(F)为F(x ) 的全体连续点组成的集合, F (x ) =F (x ), ?x ∈C (F ) , 则称随机变量X 依分布收敛至X , 若lim n n n →∞ 或称分布函数F n (x ) 依分布收敛至F (x ) ,简记为 d X ??→X n 或 d F n (x ) ??→F (x ). 定理4.4 设(X 1, X 2, , X n ) 为总体X 的样本,并设总体X 的数学期望与方差均存在,分别记为EX =μ, DX =σ2. 再记 t (n -1) , 其中与S 分别表示上述样本的样本均值与样本方差, U n = , T n = d d 则(1)F U n (x ) ??→Φ0(x ) , (2)F T n (x ) ??→Φ0(x ). 以上F U n (x ) ,F T n (x ) 与Φ0(x ) 分别表示U n , T n 及标准正态分布的分布函数. 证明(1)由于 U n = = 在总体X 的方差存在的前提下,由(林德伯格-勒维)中心极限定理,有 F U (x ) =lim P (U n ≤x ) =Φ0(x ), ?x ∈R 1. lim n →∞n →∞ n (2)证明略,有兴趣的同学可以参看附录4.3中的相关内容. 对定理4.4的说明 定理4.4的适用范围很宽泛,唯一的条件是总体的方差存在. 这样,当样本容量n 充分大时,U n 与T n 都近似地服从标准正态分布. 因此,如果总体的方差σ2已知,便可以利用枢轴量U n 近似地对 总体未知的数学期望μ进行统计推断. 如果σ2未知,便可以选用枢轴 量T n 近似地对μ进行统计推断. 数理统计期末重点知识 期末考试重点 目录 5.3 统计量及其分布 . ............................................................................................................... 1 5.4 三大抽样分布 . ................................................................................................................... 2 内容概要 . .......................................................................................................................... 2 §6.1 点估计的几种方式 . ....................................................................................................... 6 § 6.2 点估计的评价标准 . .................................................................................................... 11 内容概要 . ........................................................................................................................ 11 §7.1 假设检验的基本思想 . ................................................................................................... 19 内容概要 . ........................................................................................................................ 19 §正态总体参数假设检验 . ...................................................................................................... 26 5.3统计量及其分布 样本方差与样本标准差样本方差有两个, 样本方差s *2与样本无偏方差s *2 1s = n *2 1s =, (x -x ) ∑i n -1i =1 -2 2 n ∑(x i =1 n i -x ) 2。 - 实际中常用的是无偏样本方差s 2, 这是因为:当σ2为总体方差时, 总有 E(s *2)= n -12 σ, E(s 2) =σ2. n s 2的计算有如下三个公式可供选用: (x i ) 211122 s =(x -) =[x -]=[∑x i 2-2]. ∑∑i i n -1n -1n n -1 2 在分组样本场合, 样本方差的近似计算公式为 1k 1k 2 s =f i x i -], ∑f i (x i -) =n -1[∑n -1i =1i =1 2 1.从指数总体exp(1/θ) 中抽取了40个样品, 试求的渐进分布N (θ, 40) 2.设x 1, x 25是从均匀分布U(0,5)抽取的样本, 试求样本均值的渐进分布N , 3. 设x 1, , x 2 ?51? ?. ?212? 20 是从二点分布b(1,p)抽取得样本, 试求样本均值的渐近线分布 ?p (1-p ) ?N p , ? 20?? 4. 设x 1, , x 16是来自N (8, 4)的样本, 试求下列概率(1)P (x (16)>10) ; (2)P (x (1)>5) . 解:(1) P (x (16)>10) =1-P (x (16)≤10) =1-(P (x 1≤10)) 10 ??10-8??16 =1- Φ ??=1-0.8413=0.9370, ??0?? (2 )P (x (1)>5) =(P (x 1>5) ) 16 16??5-8?? = 1-Φ =Φ1.5??()?=0.3308. ??? ?2??? 16 16 5.4 三大抽样分布 内容概要 1. 三大抽样分布:χ2分步,F 分布,t 分布 设x 1,x 2, ?,x n 和y 1,y 2, ?,y n 是来自标准正态分布的两个相互独立的样本,则此三个统计量的构造及其抽样分布人员下表所示 今后正态总体参数的置信区间与假设检验大多数将基于这三大抽样分布 2. 一个重要的定理 设x 1,x 2, ?,x n 是来正态总体N(μ, σ2) 的的样本, 其样本均值与样本方差分别为 1n 1x =∑x i 和s 2=(x i -x ) 2, ∑n i =1n -1 则有(1)x 与s 相互独立;(2)x ~ 3. 一些重要推论 (1)设x 1, , x n 是来自正态总体N (μ, δ2) 的样本, 则有t =其中x 为样本均值, 为样本标准差. (2)设x 1, , x m 是来自N (μ1, δ1) 的样本, y 1, , y n 是来自N (μ2, δ2) 的样本, 且此两样本相互独立, 则有F = 2 2 2 2 2 (3)N (μ, δ/n ) ; 2 (n -1) ?s 2 δ2 ~χ2(n -1) . n (x -μ) ~t (n -1) , s s x 1s y 2 222 2 ~F (m -1, n -1) , 2 2 其中s x , s y 分别是两个样本方差. 若δ1=δ2, 则 F =s x 2 2 s y ~F (m -1, n -1) . 1. 在总体N (7. 6, 4) 中抽取容量为n 的样本, 如果要求样本均值落在(5. 6, 9. 6) 内的概率不小于0.95, 则至少为多少? 解:样本均值x ~N (7. 6, ) , 从而按题意可建立如下不等式 4n P (5. 6 5. 6-7. 6n x -7. 6n 9. 6-7. 64n ) ≥0. 95, n ≥1. 96或 即2Φ(n ) -1≥0. 95, 所以Φ(n ) ≥0. 975, 查表, Φ(1. 96) =0. 975, 故 n ≥3. 84, 即样本量n 至少为4. 2.设x 1, , x n 是来自N (μ, 25) 的样本, 问n 多大时才能使得P (|x -μ|<1) ≥0.=""> 解:样本均值x ~N (μ, 25 ) , 因而 n ?P (|x -μ|<1) =p=""> ?? =2Φ-1≥0.95, 所以Φ(n ) ≥0. 975, n ≥1. 96, 这给出n ≥96. 04, 即n 至少为97时, 上述概率不等式才成立. . 设x 1, , x 16是来自N (μ, δ2) 的样本, 经计算x =9, s 2=5. 32, 试求P (|x -μ|<0. 6)=""> |x -μ| 解:因为 n (x -μ) =s δ (n -1) s 2 n n -1) ~t (n -1) , 用t 15(x ) 表示服从t (15) 的随机变 δ2 量的分布函数, 注意到t 分布是对称的, 故 P (|x -μ|<0. 6)="P"> 4|x -μ|4?0. 6 <) =2t="" 15(1.="" 0405)="" -1.="" s=""> 统计软件可计算上式. 譬如, 使用MATLAB 软件在命令行输入tcdf(1.0405,15)则给出0.8427, 直接输入2* tcdf(1.0405,15)-1则给出0.6854. 这里的tcdf(x,k)就是表示自由度为可 k 的t 分布在x 处的分布函数,于是有 P (|x -μ|<0.6) =2?0.8427-1=""> 3. 设x 1, , x n 是来自N(μ, 1) 的样本, 试确定最小的常数c, 使得对任意的μ≥0, 有 P(|x | 解:由于x ~N(μ, ) , 所以P(|x | 1n g (μ) =Pμ(|| 其导函数为g ' (μ) =-n [?(n (c -μ)) -?(n (-c -μ))], 其中?(x ) 表示N(0, 1) 的密度函数, 由于c ≥0, μ≥0, 故-c -μ≥c -μ, 从而?(n (-c -μ)) ≤?(n (c -μ)), 这说明g ' (μ) ≤0, g (μ) 为减函数, 并在μ=0处取得最大值, 即 max {Φ(n (c -μ)) -Φ(n (-c -μ))}=Φ(n c ) -Φ(-n c ) =2Φ(n c ) -1. μ≥0 于是, 只要2Φ(n c ) -1≤α, 即(0≤) c ≤u (1+α) /2/n 就可保证对任意的μ≥0, 有 P(|| ?x 1+x 2? 4.设x 1, x 2是来自N (0, σ2) 的样本, 试求Y = x -x ??的分布. 2??1 解:由条件, x 1+x 2~N (0, 2σ2), x 1-x 2~N (0, 2σ2), 故 2 ?x 1+x 2??x 1-x 2?2 ~χ(1), ? ?~χ2(1), ?2σ??2σ? 又Cov (x 1+x 2, x 1-x 2) =Var (x 1) -Var (x 2) =0, 且x 1+x 2与x 1-x 2服从二元正态分布, 22 ?x 1+x 2?((x 1+x 2) /2σ) 2 故x 1+x 2与x 1-x 2独立, 于是Y = x -x ??=((x -x ) /2σ) 2~F (1, 1). 2??112 5. 设总体为N(0,1),x 1, x 2为样本, 试求常数k, 使得 2 ??(x 1+x 2) 2 P >k ?22?=0. 05. (x -x ) +(x +x ) 212?1? ?x 1+x 2?(x 1+x 2) 2Y ?~F (1, 1), z ==, 解:由上题, Y = 22 x -x ?1+Y (x 1-x 2) +(x 1+x 2) 2??1 由于Z 的取值与(0,1), 故由题目所给要求有0<><> 2 Y k P (Z >k ) =P (>k ) =P (Y >) =0. 05. 1+Y 1-k k 161. 45 =F 0. 95(1, 1) =161. 45, 这给出k ==0. 9938. 于是 1-k 1+161. 45 6.设从两个方差相等的正态总体中分别抽取容量为15,20的样本, 其样本方差分别为 S 2 s 12, s 2, 试求p (S 12>2). 22 解不妨设正太总体的方差为σ, 则有 2 14s 12 σ2 ~χ(14), 2 2 19s 2 σ2 ~χ2(19), 于是 s 12 F =2~F (14, 19). s 2 22 利用统计软件计算可算出P (s 1s 2>2) =P (F >2) =0. 0798. 譬如, 可使用MATLAB 软 件计算上式:在命令行输入1-fcdf (2,14,19)则给出0.0798, 这里的fcdf (x , k 1, k 2) 就表示 (k 1, k 2) 自由度为的F 分布在x 处的分布函数。 7.设(x 1 x 17) 是来自正态分布N (μ, σ) 的一个样本, x 与s 2分别是样本均值与样本方差。求k, 使得p (x >μ+ks ) =0. 95, _ 2 _ 解:在正态总体下, 总有 n (x -μ) ~t (n -1), 所以 s _ _ ?x -μ) P (x >μ+ks ) =P >=0.95, s ??_ 即P ≤=0.05, 故k n 是自由度是n-1的t 分布t (n-1)的0.05分倍数, 即k n =t 0. 05(n -1), 如今n=17,查表知t 0. 05(16) =-1. 7459, 从而k = -1. 7459=-0. 4234. §6.1 点估计的几种方式 1.设总体密度函数如下, x 1, , x n 是样本, 试求未知参数的矩估计 (1) p (x ; θ) = (θ-x ), 0 (2) p (x ; θ) =(θ+1) x θ, 0 1 -1- 2 , 0 x -μ θ e θ 解:(1) 总体均值E(X )= ? θ 2 θ x (θ-x ) dx =2 2 θ2 ? θ 1 (θx -x 2) dx =θ, 即即θ=3E (X ) , 3 ?=3. 故参数θ的矩估计为θ (2)总体均值E(X )= ? 1 x (θ+1) x θdx = 1-2E(X)θ+1 , 所以θ=, 从而参数θ的矩估计θ+2E(X)-1 θ?= 1-2. -1 ?E (X ) ?-1 dx =(3)由E(X )=?x x 可得θ= 1-E (X ) ??, 由此, 参数θ的矩估计0 +1?? 1 2 ??=?θ ?. ?1-? (4)先计算总体均值与方差 E(X )= 2 ?μ +∞ x 1 - x -μ θ θ dx =?t θdt +? +∞ 1 - t +∞ 1 θ θ e θdt =θ+μ -t - t E (X 2) =?x 2 μ +∞ 1 θ 1 e - x -μ θ dx =?(t +μ) 2 0+∞ +∞ 1 θ e θdt +∞ = ? +∞ t 2 θ e θdt +?2μt θdt +?μ - t 1 - t 2 1 θ θ e θdt =2θ2+2μθ+μ2. - t V a r(X )=E (X ) -(E (X )) =θ 由此可以推出θ=(X ) , μ=E (X ) -(X ) , 从而参数θ, μ的矩估计为 222 ?=s , μ?=-s . θ 2.设总体概率函数如下, x 1, , x n 是样本, 试求未知参数得最大似然估计. (1)p (x ; θ) = x -1 , 0 (2)p (x ; θ) =θc θx -(θ+1) , x >c , c >0已知, θ>1 n 解 (1) 似然函数为L (θ)=(x 1, , x n 1 , 其对数似然函数为 ln L (θ) = n ln θ+(1)(ln x 1+ +ln x n ) 2 将ln L (θ) 关于θ求导并令其为0即得到似然方程 ?ln L (θ) n =+(ln x 1+ +ln x n =0 ?θ2θ?=(1ln x ) -2 解之得θ∑i n i =1 2?ln L (θ) ?n ∑ln x i ?(ln x ) 由于=-=-- ?4n ?θ2θ4θ??θθ i 3 ? ? 4 n <> 所以θ?是θ的最大似然估计. (2)似然函数为L (θ) =θn c n θ(x 1 x n ) -(θ+1) , 其对数似然函数为 ln L (θ) =n ln θ+n θln c -(θ+1)(ln x 1+ ln x n ) 解之可得 n 1 θ?=(∑Lnx i -Inc ) -1 n i =1 ?2InL (θ) -n =2<0, 这说明θ?是θ的最大似然估计.=""> ?θθ 3.设总体概率函数如下, x 1, , x n 是样本, 试求未知参数的最大似然估计. (1)p (x ; θ) =c θx (2p (x ; θ, μ) = c -(c +1) , x >θ, θ>0, c >0已知; , x >μ, θ>0; -1 1 θ e - x -μ θ (3)p (x ; θ) =(k θ) (k θ) , θ 解:(1)样本x 1, , x n 的似然函数为 L (θ) =c n θnc (x 1 x n ) -(c +1) I {x (1)>θ} 要使L (θ) 达到最大, 首先示性函数应为1, 其次是θnc 尽可能大. 由于c>0,故θnc 是θ的单调增函数, 所以θ的取值应尽可能大, 但示性函数的存在决定了θ的取值不能大于x (1), 由此给出的θ最大似然估计为x (1) ?1n ? (2)此处的似然函数为L (θ) =() exp ?-∑(x i -μ) ?, x (1) >μ θ?θi =1? 1 n 其对数似然函数为ln L (θ, μ) =-n ln θ- ∑(x -μ) i i =1 n θ 由于 ?ln L (θ, μ) n μ =>0 ?μθ 所以, ln L (θ, μ) 是μ的单调增函数, 要使其最大, μ的取值应该尽可能的大, 由于限制 ?=x (1). μ 将ln L (θ, μ) 关于θ求导并令其为0得到关于θ的似然方程 (x i -μ) ?ln L (θ, μ) n ∑=-+i =12=0 , ?θθθ ?) ∑(x -μ i i =1n n ?=解之得θ n ?-x (1). =x (3)似然函数为 L (θ) =(k θ) -n I {θ≤x -n (1)≤x (n ) ≤(k +1) θ } . 由于L (θ)=(k θ) 是关于θ的单调递减函数, 要使L (θ)达到最大, θ应尽可能小, 但由限制{θ≤x (1)≤x (n ) ≤(k +1) θ}可以得到 x (n ) k +1 ≤θ≤x (1), 这说明θ不能小于 x (n ) k +1 , 因而θ的最大似然估 ?=计为θ x (n ) k +1 . 4.设总体概率函数如下, x 1, , x n 是样本, 试求未知参数的最大似然估计. (1)p (x ; θ)= 1 2θ e -x /θ , θ>0; (2)p (x ; θ)=1, θ-1/2 1 , θ θ2-θ11 n ?1? 解:(1)不难写出似然函数为L (θ)= ? ?2θ? n i e . -i =1 ∑x i θ n . 对数似然函数为 ln L (θ)=-n ln 2θ- ∑|x | i =1 θ |x i | ?ln L (θ)-n ∑=+i =12=0, 将之关于θ求导并令其为0得到似然方程 ?θθθ n 解之可得 而: ?=θ ∑|x | i i =1 n n . ?2ln L (θ) ?n 2∑|x |?n ==- 2-2?2(|x |) ?θθθ??θθ 2 ? ? i 2 <> 故θ?是θ的最大似然估计 (2) 此处的似然函数为L (θ)=I ? 11? ?θ- 2??2 . 它只有两个取值:0和1, 为使得似然函数取1, θ的取值范围应是x (n ) - 11 <> 11 θ的最大似然估计θ?可取(x (n ) -, x (1)+) 中的任意值. 2 2 (3) 由条件, 似然函数为 L (θ)= 1 . I n {θ1 要使L (θ)尽量大, 首先示性函数应为1, 这说明{θ1 § 6.2 点估计的评价标准 内容概要 ?=θ?(x ,…,x ) 是θ的一个估计量, n 是样本容量, 若对1. 相合性设θ∈Θ为未知参数, θ1n n n 任何一个ε>0,有 ?-θ|>ε) =0, ?θ∈Θ, lim P (|θn n →∞ ?为参数θ的相合估计. 则称θn ? 相合性本质上就是按概率收敛, 它是估计量的一个基本要求, 即当样本量不断增大时, 相合估计按概率收敛于未知参数; ? ? 矩法估计一般都是相合估计; 在很一般的条件下, 最大似然估计也是相合估计. ?(x ,…,x ) 是θ的一个估计, θ的参数空间为Θ, 若对?θ∈Θ, 有 2.无偏性设=θ1n n ?) =θ E (θ 则称θ?是θ的无偏估计, 否则称为有偏估计. ?) =θ, 则称θ?是θ的渐近无偏估计. 假如对任意的θ∈Θ, 有lim E (θ n →+∞ ?的两个无偏估计, 如果对任意的θ∈Θ有 3.有效性设θ?1是θ2 ?) ≤Var (θ?) , Var (θ12 ?有效. 且至少有一个θ∈Θ使得上述不等号严格成立, 则称θ?1比θ2 4.均方误差设θ?是θ的一个估计(无偏的或有偏的), 则称 ?) =E (θ?-θ) 2=Var (θ?) +(E (θ?-θ)) 2 MSE (θ ?-θ) 也小, 所以均方误θ?不仅方差较小, 而且偏差(E θ为θ的均方误差. 均方误差较小意味着: 差是评价估计的最一般标准. ?使均方误差一致最小的估计量一般是不存在的, 但两个估计好坏可用均方误差评价: ?在无偏估计类中使均方误差最小就是使方差最小. ?为样本1.总体X~U(θ, 2θ), 其中θ>0是未知参数, 又x 1, , x n 为取自该总体的样本, x 均值. ?=(1)证明θ 2 是参数θ的无偏估计和相合估计; 3 (2)求θ的最大似然估计, 它是无偏估计吗?是相合估计吗? 2. 设x 1, , x n 是来自密度函数为p (x ; θ) =e -(x -θ) , x >θ的样本, (1) 求θ的最大似然估计θ?1, 它是否是相合估计?是否是无偏估计? ?, 它是否是相合估计?是否是无偏估? (2) 求θ的矩估计θ2 ?的均方误差达到最小的c, 并将之与?=x -c 的估计, 求使得θ(3) 考虑θ的形如θc c (1) θ?1, θ?2的均方误差进行比较. 解: (1)似然函数为 L (θ) =∏e i =1 n { -(x i -θ) I {x i >θ} } ?n ? =exp ?-∑x i +n θ?I {x (1) >θ}. ?i =1? ?=x . 又显然L (θ) 在示性函数为1的条件下是θ的严增函数, 因此θ的最大似然估计为θ1(1) x (1) 的密度函数为f (x ) =ne -n (x -θ) , x >θ, 故 +∞+∞1-n (x -θ) ?E (θ1) =?xne dx =?(t +θ) ne -nt dt =+θ, 00n ?) →θ(n →+∞) 且 故θ?1不是θ的无偏估计, 但是θ的渐近无偏估计. 由于E (θ1 ?2) =+∞x 2ne -n (x -θ) dx =+∞(t 2+2θt +θ2) ne -nt dx =2+2θ+θ2, E (θ1?0?0 n 2n ?) =2+2θ+θ2-(1+θ) 2=1→0, V a r (θ1 n n n 2n 2 这说明θ?1是θ的相合估计. (2) 由于E (X ) = ? +∞ xe -(x -θ) dx =θ+1, 这给出θ=EX -1, 所以θ的矩估计为 2-n (x -θ) 2?=-1. 又E (X 2) =x ne dx =θ+2θ+2, 所以V a r (X ) =1, 从而有 θ2?0 +∞ ?) =E () -1=θ, V a r (θ?2) =1V a r (X ) =1→0(n →+∞), E (θ2 n n ?既是θ的无偏估计, 也是相合估计. 这说明θ2 ?=x -c 的估计类, 其均方误差为 (3) 对形如θc (1) ?) =V a r x --c ) +(Ex -c -θ) =M SE (θ(1) (1) c 2 112 +(-c ) , 2 n n 因而当c 0= 1?) =1达到最小, 利用上述结果可以算出 时, M SE (θc 0 n n 2 ?) =2, M SE (θ?) =1, M SE (θ12 n n 2 1 的均方误差最小. n ?) ≤M SE (θ?) ≤M SE (θ?) , 所以在这三个估计中, θ?c =x (x ) -故有M SE (θ12c 00 3. 设总体X ~Exp (1/θ), x 1, , x n 是样本, θ的矩估计和最大似然估计都是, 它也是θ ?=a , 找的相合估计和无偏估计, 试证明在均方误差准则下存在优于的估计(提示:考虑θa 均方误差最小者). 证:由于总体X ~Exp =(1/θ), 所以E () =θ, V a r () =估计类, 其均方误差为 22 a ?) =Var (a ) +(E (a ) -θ) =θ+(a -1) 2θ2. M SE (θa n 2 θ2 n ?=a 的. 现考虑形如θa 将上式对a 求导并令其为0, 可以得到当a 0= n ?) 最小, 且 时, M SE (θa n +1 ?) =MSE(θa 0 1 <θ2=mse(). n=""> θ2 这就证明了在均方误差准则下存在一个优于的估计. 这也说明,有偏估计有时不比无偏估计差. 18. 设x 1, x 2独立同分布,其共同的密度函数为 p (x ; θ) = (1)证明:T 1= 3x 2 θ 3 , 0 27 (x 1+x 2) 和T 2=max {x 1, x 2}都是θ的无偏估计; 36 (2)计算T 1和T 2的均方误差并进行比较; (3)证明:在均方误差意义下,在形如T C =c max {x 1, x 2}的估计中T 最优. 解:(1)先计算总体均值为E (X ) = ? θ x ? 3x 2 32 E (T ) =?2E (X ) =θ, 这说=θ,故1 34θ3 明T 1是θ的无偏估计. 又总体分布函数为F (x ; θ) = ? x 3μ2 x 3=() , 0 θθ max {x 1, x 2},则密度函数为 f (y ; θ) =2F (y ; θ) p (y ; θ) = 7θ6y 676 dy =?θ=θ 于是有E (T 2) =?60θ667 这表明T 2也是θ的无便估计. (2)无偏估计的方差就是均方误差,由于 6y 5 θ 6 , 0 E (x 1) =?x ? 2 2 θ 2 3x 2 θ3 3 dx =θ2, 5 Var (x 1) =E (x 1) -E (x 1) 2= 故有 323 θ-(3θ) 2=θ2, 5480 MSE (T 1) =Var (T 1) = 又 4831 ?2Var (x 1) =?θ2=θ2. 998030 θ E (Y ) =?y ? 22 6y 5 32 =θ, 6 4θ 3632 Var (Y ) =E (Y 2) -(EY ) 2=θ2-(θ) 2=θ, 47196 从而 MSE (T 2) =Var (T 2) = 49321 ?θ=θ2. 3619648 由于MSE (T 1) >MSE (T 2), 因此在均方差意义下,T 2优于T 1. (3)对形如T c =cmax {x 1, x 2}的估计有E (T c ) = 632 c θ, E (T c ) =c 2θ2,故 74 312 MSE (T c +) =E (T C -θ) 2=E (T c 2) -2θE (T c ) +θ2=(c 2-c +1) θ2, 47 12 72 因此当c == 8 时, 上述均方误差最小, 所以在均方误差意义下, 在形如7 T c =c m a x x {1, x 2}的估计中, T 最优. 3.设x 1, , x n 是来自二点分布b (1, p ) 的一个样本, (1) 寻求p 2的无偏估计; (2) 寻求p (1-p ) 的无偏估计; (3) 证明 1 的无偏估计不存在. p 解:(1)是p 的最大似然估计, 2是p 2的最大似然估计, 但不是p 2的无偏估计, 这是因为 E (2) =Var () +[E ()]2= 由此可见p 2= p (1-p ) p n -12 +p 2=+p ≠p 2, n n n n ?2?2 是的无偏估计. -p ??n +1?n ? (2)(1-) =-2是p (1-p ) 的最大似然估计, 但不是p (1-p ) 无偏估计, 这是因为 E (-2) =p -( p (1-p ) n -1n +p 2) =p (1-p ) ≠p (1-p ), 由此可见x (1-x ) 是n n n -1 p (p -1) 的一个无偏估计, 1 (3)反证法,倘若g (x 1, L , x n ) 是的无偏估计,则有 p x 1, x n ∑g (x 1, x n ) p ∑ n n ∑ i =1 n x i n - (1-p ) ∑x i i =1 n = 1 p 或者 x 1 x n ∑g (x , x 1 n ) p i =1 x i +1 n - (1-p ) ∑x i i =1 -1=0 上式是p 的n +1次方程, 它最多有n +1个实根, 而p 可在(0,1)取无穷多个值, 所以不论取什么形式都不能使上述方程在0 <1上试成立,> 1 的无偏估计不存在. p 3.0.50,1.25,0.80,2.00是取自总体X 的样本, 已知Y =lnX 服从正态分布N (μ,1). (1) 求μ的置信水平为95%的置信区间; (2) 求X 的数学期望的置信水平为95%的置信区间. 解 (1) 将数据进行对数交换, 得到Y =lnX 的样本值为:-0.6931,0.2231,-0.2231,0.6931.它可看作是来自正态分布N (μ,1) 的样本, 其样本均值为=0,由于σ=1已知, 因此, μ的置信水平为95%的置信区间为: -u 1-α/2/n , +u 1-α/2/n =[-0.9800,0.9800]. (2) 由于E X =e μ+1 2 [ ] 是μ的严增函数, 利用(1)的结果, 可算得X 的数学期望的置信水平为95% 0. 98+0. 5 的置信区间为[e -0. 98+0. 5, e ]=[0.6188,4.3929]. 4.用一个仪表测量某一物理量9次, 得样本均值=56.32,样本标准差s=0.22. (1) 测量标准差σ大小反映了测量仪表的精度, 试求σ的置信水平为0.95的置信区间; (2) 求该物理量真值的置信水平为0.99的置信区间. 2 解 (1)此处(n -1) s =8×0.22=0.3872,查表知χ0. 025(8)=2.1797,χ0. 975(8) =17.5345,σ的 2 2 22 1-α置信区间为 ?(n -1) s 2(n -1) s 2??0. 38720. 3872? , , ?=???=[0.0221,0.776] χ(n -1) 17. 53452. 1797χ(n -1) ?α/2???1-α/2 从而σ的置信水平为0.95的置信区间[0.1487,0.4215]. (2) 当σ未知时, μ的1-α置信区间为 [-t 1-α/2(n -1) s /n , +t 1-α/2(n -1) s /n ]. 1 注:这里s 0=2s 0 l 为最接近于 s s + m 2(m -1) n 2(n -1) 4x 4y 的整数 查表得t 1-0. 005(8)=3.3554,因而μ的置信水平为0.99的置信区间为 [56.32-3.3554×0.22/,56.32+3.3554×0.22/9]=[56.0739,56.5661]. §7.1 假设检验的基本思想 内容概要 1. 假设 参数空间Θ={θ}的非空子集或有关参数θ的命题,称为统计假设,简称假设。 原假设,根据需要而设立的假设,常记为H 0 : θ∈Θo . 备择假设,在原假设被拒绝后而采用(接受) 的假设,常记为H 1 : θ∈Θ1. 2. 检验 个结果: “原假设不正确”,称为拒绝原假设,或称检验显著; “原假设正确”,称为接受原假设,或称检验不显著 3. 检验问题 由原假H 0和备择假设H 1组成的一个需要作判断的问题称为检验问题。 参数检验问题,两个假设都是由有关参数的命题组成的检验问题; 非参数检验问题,两个假设都是由有关分布的命题组成的检验问题。 常用的参数的假设检验问题有如下三种,其中θ0是已知常数 (1) H 0 :θ≤θo vs (2) H 0 :θ≥θo vs (3) H 0 :θ= θo vs H 1 : θ>θo H 1 : θ<θo h="" 1="" :=""> 对原假设H 0 : θ∈Θo . 作出判断的法则称为检验法则,简称检验。检验有两 其中(1)与(2)又称单侧检验问题,因为一个假设位于另一个假设的一侧,(3)称为双侧检验问题,因为备择假设位于原假设的两侧。 4. 两类错误及其发生的错误 原假设H 0正确,但被拒绝,这种判断错误称为第一类错误,其发生概率称为犯第一类错误的概率,或称拒真概率,常记为α; 原假设H 0不真,但被接受,这种判断错误称为第二类错误,其发生概率称为犯第二类错误的概率,或称受伪概率,常记为β. 5.假设检验的基本步骤 (1)建立假设. 根据要求建立原建设H 0和备择假设H 1. (2)选择检验统计量,给出拒绝域W 的形式. ?用于对原假设H 0作出判断的统计量称为检验统计量; ?使原假设被拒绝的样本观察值所在区域称为拒绝域,常用W 表示; 反之,一个检验法则唯一确定一个拒绝域W . ?一个拒绝域W 唯一确定一个检验法则, (3) 选择显著性水平α(0<><1) .="" 只控制犯第一类错误的概率不超过α的检验称为水平为α的检验,或称为显著性检验,但也不能使α过小(α过小会导致β增大)="" ,在适当控制α中制约β,最常用的α="0." 05,有时也选择α="0." 10.="" 或者α="0."> (4) 给出拒绝域. 由概率等式P (W ) =α确定具体的拒绝域. (5) 作出判断. ?当样本(x 1,..., x n ) ∈W , 则拒绝H 0, 即接受H 1; ?当样本(x 1,..., x n ) ∈W , 则接受H 0. 6. 势函数设检验问题H 0:θ∈Θ0 vs H 1 θ:∈Θ1的拒绝域为W , 则样本观测值 x 1, , x n 落在拒绝域W 内的概率称为该检验的势函数, 记为 g (θ) =P θ((x 1,..., x n ) ∈W ), θ∈Θ0?Θ1 由势函数g (θ) 容易得到犯两类错误的概率 ?α(θ), θ∈Θ0, g (θ) =? ?1-β(θ), θ∈Θ1. 1. 设x 1,..., x n 是来自N (μ, 1) 的样本, 考虑如下假设检验问题 H 0:μ=2vs H 1:μ=3, 若检验由拒绝域W =x ≥2. 6确定. (1) 当n =20时求检验犯两类错误的概率; (2) 如果要使得检验犯第二类错误的概率β≤0. 01, n 最小应取多少? (3) 证明:当n →+∞时,α→0, β→0. 解:(1) 由定义知,犯第一类错误的概率为 } α=P (x ≥2. 6|H 0) =P ?x -22. 6-2? ?=1-Φ(2. 68) =0. 0037≥, 20?20?? 这是因为在H 0成立下,x ~N (2, 20). 而犯第二类错误的概率为 ?? β=P (x <2.6|h 1)="P"><=φ(-1.79) =1-φ(1.79)="0.0367" 这是因为在h="" 1成立下,~n=""> (2) 若使犯第二类错误的概率满足 ?? β=P (<2.6|h 1)="P"><> 即1-Φ0. 或Φ4≤0.01, ( 909. ≥ n ≥33.93,, 查表得:因此,2.33, 即n 最小应取34, 才能使检验犯第二类错误的概率β≤0. 01, n (3) 在样本量为n 时,检验犯第一类错误的概率为 α=P (≥2.6|H 0) =P 检验犯第二类错误的概率 ?? ≥=1-Φ→0(n →∞), ?? β=P (<2.6|h 1)="P"><=φ(-→0(n> 注:从这个例子可以看出,要使检验犯两类错误的概率都趋于零,必须样本容量无限增 大才行,这一结论在一般场合仍然成立。但是在实际中,样本容量很大往往不可行,故在一 般情况下不可能做到犯两类错误的概率都很小。 2. 设x 1, x 2, ?, x 10是来自0-1总体B (0,1)的样本,考虑如下检验问题: H 0: p =0.2 vs H 0: p =0.4 取拒绝域W ={≥0.5},求该检验犯两类错误的概率。 解:x 1, x 2, ?, x 10~B (0,1),则10~B (10,p ) ,于是犯两类错误的概率分别为: 1 α=P (≥0.5|H 0) =P (10≥5|H 0) =∑(10k )() k =510 k ()410-k =0.0328, 检验犯第二类错误的概率 2 β=P (<0.5|h 1)="P"><5|h 1)="∑(10k"> k =04 k 3 (5)10-k =0.6331. 讨论:这里α=0。0328已经很小了,但是β=6331却很大,在样本容量n =10固定下,要 使α变小,则β就会变大。为了进一步说明这一点,我们试着改变拒绝域为W ={≥0.6}, 则这时检验犯两类错误的概率分别为 α=P (≥0.6|H 0) =P (10≥6|H 0) =∑ k =6 10 ?10??1??4? k ?? 5? 5??????? k 10-k ?10??1??4? =0.0328- 5?? 5? 5?=0.0328-0.0264=0.0064, ?????? ?10??2??3? β=P (<0.6h 1)="P"><6h 1)="∑" ???=""> k =0?k ??5??5? 5 5 5 k 10-k 55 ?10??2??3? =0.6331+ ??? ?=0.6331+0.2007=0.8338. ?5??5??5? 这一现象在一般场合也是对的,即在样本量n 固定下,减小α必导致增大β,减小β也 必导致增大α. 3.设x 1, x 2, ?, x 16是来自正态总体N(μ,4) 的样本,考虑检验问提H 0: μ= 6 vs H 0: μ≠ 6 拒绝域取为W ={|-6|≥c }, 试求c 使得检验的显著性水平为0.05,并求检验在μ=6.5处犯第二类错误的概率。 解:在H 0为真的条件下,~N (6,1/4) ,因而由 c ??-6 P (|-6|≥c |μ=6) =0.05, ?P ≥?=1-Φ(2c ) =0.025 ?0.50.5? ?Φ(2c ) =0.975?2c =1.96?c =0.98 即当c =0.98时,检验的显著性水平为0.05 检验在μ=6.5处犯第二类错误的概率为 β=P (|-6|<0.98|μ=6.5) =p=""> -6.5 <2?0.48)> =Φ(0.96)-Φ(-2.96) =Φ(0.96)+Φ(2.69)-1=0.83. 4. 设总体为均匀分布u (0, θ), x 1, x 2, , x n 是样本,考虑检验问题 H 0:θ≥3 vs H 1:θ<> 拒绝域取为W =x (n )≤2.5, 求检验犯第一类错误的最大植α。若要使的该最大植α不超过0.05, n 至少应取多大 {} ?nx n -1 ,0 解:均匀分布U(0,θ) 的最大次序统计量f n (x )=?θn ,因而检验犯第一 ?0,其他? 类错误的概率为 α(θ)=P (x (n )≤2.5H 0) =? 2.5 ?2.5? n n = ?, θ?θ? n x n -1 n ?2. 5? 它是θ的严减函数,故其最大值在θ=3处达到,即α=α(3)= ?. 3?? 若要使得α(3)≤0. 05, 则要求n l n (2.5/3)≤ln 0. 05, 这给出n ≥16.43,即n 至少为17. 5. 设总体密度函数为f (x )=(1+θ)x , 0≤x ≤1, θ≥0. 为检验 θ H 0:θ=1 VS H 1:θ<> 现观测1个样本,并取拒绝域为W ={x ≤0. 5},试求检验的势函数以及检验两类错误的概率。 解:由定义,检验的势函数g (θ)是检验拒绝原假设的概率,为 θθ+1 g (θ) =P 。 0(x ≤0.5) =?0(1+θ)x dx =0. 5 0. 5 1+1 当θ=1时,势函数就是检验犯第一类错误的概率,为α=0.5=0.25; 当θ=0时,1减去势函数就是检验犯第二类错误的概率,它是θ的函数,为 β(θ)=1-0. 5θ+1, 0<><1,> 9. 设x 1, , x n 是来自U(0,θ) 的一个样本,对如下的检验问题 H 0:θ≤ 11 VS H 1:θ>, 22 已给出拒绝域W =x (n )≥C , 其中x (n )为样本的最大次序统计量。 (1) 求此检验的势函数; (2) 若要求检验犯第一类错误的概率不超过0.05(即α(θ≤0. 05)) ,如何确定C ? (3) 若在(2)的要求下进一步要求检验θ= {} 3 处犯第二类错误的概率不超过0.02(即4 β(θ≤0. 02)) ,n 至少要取多少? (4) 如今n =20, x (20)=0. 48, 对此检验问题作出判断。 解:(1)此检验的势函数为 g (θ)=P x (n )≥c =1-P x (n ) ?0, 当θ≤c , ? =??c ?n , ?1- ?当θ>c . ??n ? 可见,在θ>c 时,势函数g (θ)是θ的严增函数 (2)在H 0成立下,犯第一类错误的概率为α(θ)=g (θ),故由题意知,应有 ()() 1?c ? g (θ)=1- ?≤0.. 05, θ≤. 2?θ? 由于g (θ)在θ= n 1?1?n 处达到最大值,故只要使g ?=1-(2c )=0.. 05, 即可实现,由此解出2?2? c = 1 (0. 95). 譬如,在n =5时,c =0.4873;n =10时, c =0.4974。 2 (3)在备择假设H 1成立下,犯第二类错误的概率为 1?c ? g (θ)=1-g (θ)= ?, θ≤. 2?n ? 31c 由题意知,要求在θ=处有β(θ) ≤0. 02, 即() n ≤0. 02, 若把(2)中的c =(0. 95) n 代入, 3424 可得n ≥ 1 n ln 95-ln 2 =9. 52 ln 3-ln 2 可见,若取n =10即可使θ= 3 处犯第二类错误达到概率不超过0.22。 4 (4)如果样本量n =20,则其拒绝域为 w ={x (n ) 1 ≥c 0},其中c 0=(0. 95) 20=0. 4987 2 1 2 1 如今x (n ) =0. 48 §正态总体参数假设检验 1.单个正态总体均值的假设检验 检验法条件 原假设H 0u <=u 0u="">=u 0u =u 0u >=u 0 备择假设H 1检验统计量u >u 0u u 0u t =u = 拒绝域{u ≥u 1-α} u 检验σ已知 {u ≤u α}{u ≥u 1-σ} {t ≥t 1-α n -1} t 检验σ未知 u <=u 0u="u"> {t ≤t α (n -1)} n -1)}({t ≥t 1-α 注:表中 和σ 分别为来自正态总体的样本的均值和标准差。 2. 假设检验与置信区间的关系 双侧检验问题:H 0:u =u 0 vs H 1:u ≠u 0的接受域可定出正态均值u 的 1-α置信区间; 单侧检验问题:H 0:u ≤u 0 vs H 1:u >u 0的接受域可定出正态均值u 的 1-α置信上限; 单侧检测问题:H 0:u ≥u 0 vs H 1:u ≤u 0的接受域可定出正态均值u 的1-α置信下限; 3. 两个正态均值差的假设检验 22 注:表中和s x 分别来自正态总体N(μ1, σ12) 的样本x 1, , x m 的均值和方差;和s y 2 分别为来自正太总体N(μ2, σ2) 的样本y 1, , y n 的均值和方差,且 s 2w = 22 (m -1) s x +(n -1) s y m +n -2 22 s y s x , s 0=+, l = m n , 2 4s 0 s s + m 2(m -1) n 2(n -1) 4x 4y . 4.单个正态总体方差的假设检验 注:和s 2分别来自正态总体N(μ, σ2) 的样本x 1, , x n ; 5.两个正态总体方差的假设检 注:表中s 2 x 来自正态总体N(μ1, σ21) 的样本x 1, , x m 的方差;N(μ22, σ2) 的样本y 1, , y n 的方差 s 2y 为来自正太总体 1. 某厂使用两种不同的原料生产同一类型产品,随机选取使用原料A 生产的样品22件,测得其平均质量为23.6(k g), 样本标准差为0.57(k g) 。取使用原料B 生产的样品24件,测得其平均质量为2.55(k g) ,样本边准差为0.48(k g) 。设产品质量服从正态分布,两个样本独立。问能否认为使用原料B 生产的产品质量较使用原料A 显著大(取α=0. 05) ? 解:设X 为使用原料A 生产的产品质量,Y 为使用原料B 生产的产品质量,则 X ~N (μ1, σ2) ,Y ~N (μ2, σ2) ,由问题的陈述,我们看到这是关于两总体均值的检验 问题,且为了能够显著地认为使用原料B 生产的产品质量较使用原料A 大,必须见该陈述作为备择假设,只有当拒绝域与之相对的原假设使,才能说明使用B 生产的产品的平均质量较使用原料A 显著大,因此,可建立如下假设检验问题 H 0:μ2≤μ1Vs. H 1:μ2>μ1 为完成此假设检验,应先对两总体的方差是否相等进行检验,若接受σ1=σ2,可以使用两样本t 检验;若σ1=σ2成立,则可以近似t 检验。 对于检验问题H 00:σ1=σ2vs. H 01:σ1≠σ2,可计算如下检验统计量 2 s x 0. 572 =1. 4102 F =2= s y 0. 482 22 22 2222 若取α=0. 05,则F 0. 975(21, 23)=2. 340, F 0. 025(21, 23)= 1 =0. 4201, 拒绝域为 F 0. 97523, 21},观测值未落入拒绝域内,由此可以认为两个总体的方差W ={F ≤0. 4201或F ≥3. 3404 相等。 下面我们在方差相等的假定下检验上述关于均值的假设,此处可使用两样本t 检验,若 },由所给条件,计算得 取?=0. 05, 则t 0. 95(44)≈u 0. 95=1. 645, 故拒绝域为W ={t ≥1. 645 21?0. 572+23?0. 482 s w ==0. 5249, 21+23t = ==1.2264, w 由于1.2264<1.645,因此在显著性水平?=0. 05时,应接受原假设h=""> 料B 生产的产品平均质量没有显著地超过使用原料A 生产的产品平均质量。 讨论:若改变检验问题的一对假设为 ' H 0:μ2≥μ1vs H 1' :μ2<> },如今t =1.2264〉-1.645,故应接受原假设H 0' :μ2≥μ1。 则其拒绝域为W ={t ≤-1. 645 把两对假设联合起来考察可以看出,既接受原假设H 0:μ2≤μ1也接受原假设 ' H 0:μ2≥μ1,造成这一现象的原因是因为两对假设检验问题的接收域有共同部分(见图 7.1) ,而统计量的值正好落在这个公共区域内。 图7.1 这一现象并不是很少见的,在其他检验问题中也可能出现,只要检验统计量的取值落入 ?',这说明在假设检验中“不拒绝原假设”的含义是丰富的,处理要谨慎。 2. 设X ~N 具体如下: (μ, σ), Y ~N (μ, σ). 从总体X 与总体Y 各取容量分别为7和5的样本, 1 2 1 2 22 设两样本独立,取α=0. 05, 2 (1)检验假设H 0:σ12=10σ2 vs H 1:σ1≠10σ2; 22 (2)利用(1)的结果,检验H 0:μ1-μ2=10 vs H 1:μ1-μ2≠10 解:以, 分别表示来自两个总体的样本的样本均值,s x , s y 分别为其样本方差. m , n 分别为两个样本量, 此处m =7,n =5. 2 (m -1)s x (1) 由于 22 σ12 ~χ(m -1), 2 (n -1)s y 2 2σ2 ~χ2(n -1), 且二者独立, 故对假设检验问题 222 vs H 1:σ1≠10σ2; 在原假设成立下, 检验统计量 H 0:σ12=10σ2 22s x s x /σ12 F ==22~F (m -1, n -1), 2 10s y s y /σ2 拒绝域为 W ={F ≤F α/2(m -1, n -1)或F ≥F 1-α/2(m -1, n -1)}, 由于m =7, n =5, α=0. 05, 表知 F 0. 975(6, 4)=9. 20, F 0. 025(6. 4)= 1F 0. 9754, 6= 1 =0. 1605, 6. 23 或F ≥9. 20此处由样本数据算得 故检验拒绝域W =F ≤0. 1605 22s x =913. 25, s y =78. 801, {} 从而F = 913. 25 =1. 1589 10?78. 801 2 由于检验统计量未落入拒绝域,故接受原假设,认为σ12=10σ2 2 (2) 由(1)可知假设σ12=10σ2=10σ2, 在此条件下, 22 (m -1) s x +10(n -1) s y 2 (m -1) s x 2 (n -1) s y 2σ2 10σ2 又 = σ12 + ~χ2(m +n -2), 2 ??σ12σ2??101?2? -~N μ1-μ2, +=N μ-μ, +?σ?, ?2 1 m n m n ?????? 故在μ1-μ2=10时,检验统计量 t = ~t (m +n -20), 此处m =7.n =5,若取α=0. 05,查表知t 0. 975(10) =2. 2281,检验拒绝域为W =t ≥2. 2281,现由样本可计算得到 } (110-97. 4-10) t = 101+75 =0. 2193 6?913. 25=10?4?78. 801 10?10 现检验统计量值为落入拒绝域,故接受原假设。范文五:数理统计期末重点知识