


 VIP呆呆
VIP呆呆
范文一:多元线性回归分析实例
由散点图可知:
X1水分与人们对水果的喜爱程度具有明显的线性相关性; X2甜度对人们喜爱水果的影响程度相关性不明显
下面进行Y与x1、x2之间的线性拟合:
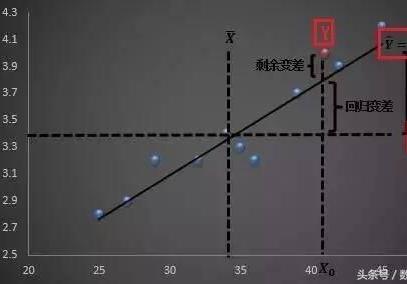
调整后的R方为0.932,趋近与1,模型对样本数据点拟合优度较高,其中喜爱程度的总变差中93.2%可以用水分和甜度的变化来解释。变量被解释得比较好。
H0:β2=0 (水果甜度和人们对水果的喜爱程度无显著线性关系) H1:β2≠0(水果甜度和人们对水果的喜爱程度有显著线性关系)
P值0.000,小于0.05,拒绝原假设,接受对立假设,即水果甜度和人们对水果的喜爱程度有显著线性关系
线性回归方程:
Y=4.395x1+4.326x2+37.955
方程的解释:
在水果甜度不变的前提下,水果水分每增加1个单位,人们对水果的喜爱程度增加4.395个单位
在水果水分不变的前提下,水果甜度每增加1个单位,人们对水果的喜爱程度增加4.326个单位
残差的正态性检验:
H0:该模型的误差项符合正态性检验 H1:该模型的误差项不符合正态性检验
K-S检验的P值为0.763,大于0.05,接受原假设,该模型符合正态性检验,说明误差项的正态性假设是合理的。 残差的方差齐性检验:
上述散点图水果水分与误差近似分布在一条水平的带状线中,那么就可以认为残差的齐性假设是合理的。
散点图水果甜度与误差近似分布在一条垂直的带状线中,可以认为残差的齐性假设是不合理的。
范文二:多元线性回归分析实例
由散点可知:图图图图
X1水分与人水果的喜程度具有明的性相性,图图图图图图图图图图图图图图图图图图图图
X2甜度人喜水果的影响程度相性不明图图图图图图图图图图图图图图图图图图
下面行图图Y与x1、x2之的性合:图图图图图图图
b模型汇汇
RR 方汇整 R 方模型汇准 汇的汇差估更改汇汇量
R 方更改F 更改df1df2Sig. F
更改
a1.970.942.9322.796.94297.065212.000
a. 汇汇汇量: (常量), x2, x1。
b. 因汇量: y
图整后的R方图0.932,近与图图图1,模型本数据点合度高,其中喜程度的差中图图图图图图图图图图图图图图图图图图图图图图图图93.2%可以用水分和甜度的化来解。图图图图图图图图图图图图图量被解得比好。
aAnova
dfFSig.模型平方和均方
b11517.9052758.95397.065.000回汇
93.828127.819残差
1611.73314汇汇
a. 因汇量: y
b. 汇汇汇量: (常量), x2, x1。
H0:β = 0,i=1,2,水果水分和甜度与人水果的喜程度无著性系,图图图图图图图图图图图图图图图图图 i
H1:β 不全零,图图图i=1,2,,水果水分和甜度与人水果的喜程度有著性系,图图图图图图图图图图图图图图图图图i
SSR=1517.905 SSE=93.828 SST=1611.733MSR= SSR/(P-1)=758.953
MSE= SSE/(N-P)=7.819
F=MSR/MSE=97.065
由回方程著性的概率图图图图图图图图图图图图0.000,小于著性水平图图图图图0.05,水果水分和甜度与人水果的图图图图图
喜程度之具有明性,被解量与解量全体的性图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图系是著的,可建立性方程。图图图图图图图图图图图图
回系数的著性归归归归归归归归归:
a系数
tSig.模型非汇准化系数汇准系数
B汇准 汇差汇用版
1(常量)37.9553.34911.333.000
x14.395.335.91913.125.000
x24.326.727.4165.949.000a. 因汇量: y
H0:β=0 ,水果水分和人水果的喜程度无著性系,图图图图图图图图图图图图图图图图图 1
H1:β?0,水果水分和人水果的喜程度有著性系,图图图图图图图图图图图图图图图图图 1
P图0.000,小于0.05,拒原假,接受立假,即水果水分和人水果的喜程度图图图图图图图图图图图图图图图图图图图图图图图图图图图图有图图著
性系图图
H0:β=0 ,水果甜度和人水果的喜程度无著性系,图图图图图图图图图图图图图图图图图 2
H1:β?0,水果甜度和人水果的喜程度有著性系,图图图图图图图图图图图图图图图图图 2
P图0.000,小于0.05,拒原假,接受立假,即水水果甜度和人水果的喜程度图图图图图图图图图图图图图图图图图图图图图图图图图图图图图有图图著性系图图
回方程:图图图图y=0.419x+29.048
方程解:工作图图图图图图图图图图图图图图图增加一个位,年收入增加每0.419个位图图
H0:β=0 ,水果甜度和人水果的喜程度无著性系,图图图图图图图图图图图图图图图图图 2
H1:β?0,水果甜度和人水果的喜程度有著性系,图图图图图图图图图图图图图图图图图 2
P图0.000,小于0.05,拒原假,接受立假,即水果甜度和人水果的喜程度图图图图图图图图图图图图图图图图图图图图图图图图图图图图有图图图著性图系
图图图图图性回方程:
Y=4.395x1+4.326x2+37.955
方程的解:图图
在水果甜度不的前提下,水果水分图图图增加每1个位,人水果的喜程度增加图图图图图图图图图图图图图图图4.395个位图图
在水果水分不的前提下,水果甜度图图图增加每1个位,人水果的喜程度增加图图图图图图图图图图图图图图图4.326个位图图
残差的正性:归归归归归
正汇性汇汇
aKolmogorov-Smirnov
Shapiro-Wilk
汇汇量
df
Sig.
汇汇量
df
Sig.
Unstandardized Residual
.114
15
*.200
.964
15
.763*. 汇是汇汇著水平的下限。真
a. Lilliefors 汇著水平修正
H0:模型的差符合正性图图图图图图图图图图图图图图
H1:模型的差不符合正性图图图图图图图图图图图图图图图
K-S图图的P图图0.763,大于0.05,接受原假,模型符合正性,明差的图图图图图图图图图图图图图图图图图图图正性假是合理的。图图图图图图图图图
残差的方差性:归归归归归
上述散点水果水分与差近似分布在一条水平的状中,那就图图图图图图图图图图图图图图图图图图图图图图图图图图
可以残差的性假是合理的。图图图图图图图图图图图图图图
散点水果甜度与差近似分布在一条垂直的状中,可以残差的性假是图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图图合理的。
范文三:多元线性回归实例分析
SPSS--回归-多元线性回归模型案例解析!(一)
多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为:
毫无疑问,多元线性回归方程应该为:
上图中的 x1, x2, xp分别代表“自变量”Xp截止,代表有P个自变量,如果有“N组样本,那么这个多元线性回归,将会组成一个矩阵,如下图所示:
那么,多元线性回归方程矩阵形式为:
其中: 代表随机误差,其中随机误差分为:可解释的误差和不可解释的误差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样) 1:服成正太分布,即指:随机误差必须是服成正太分别的随机变量。
2:无偏性假设,即指:期望值为0
3:同共方差性假设,即指,所有的 随机误差变量方差都相等
4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。
今天跟大家一起讨论一下,SPSS---多元线性回归的具体操作过程,下面以教程教程数据为例,分析汽车特征与汽车销售量之间的关系。通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。数据如下图所示:
点击“分析”——回归——线性——进入如下图所示的界面:
将“销售量”作为“因变量”拖入因变量框内,将“车长,车宽,耗油率,车净重等10个自变量拖入自变量框内,如上图所示,在“方法”旁边,选择“逐步”,当然,你也可以选择其它的方式,如果你选择“进入”默认的方式,在分析结果中,将会得到如下图所示的结果:(所有的自变量,都会强行进入)
如果你选择“逐步”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F统计量的概率值进行筛选,最先进入回归方程的“自变量”应该是跟“因变量”关系最为密切,贡献最大的,如下图可以看出,车的价格和车轴跟因变量关系最为密切,符合判断条件的概率值必须小于0.05,当概率值大于等于0.1时将会被剔除)
“选择变量(E)
点击“统计量”弹出如下所示的框,如下所示:
在“回归系数”下面勾选“估计,在右侧勾选”模型拟合度“ 和”共线性诊断“ 两个选项,再勾选“个案诊断”再点击“离群值”一般默认值为“3”,(设定异常值的依据,只有当残差超过3倍标准差的观测才会被当做异常值)点击继续。
提示:
共线性检验,如果有两个或两个以上的自变量之间存在线性相关关系,就会产生多重共线性现象。这时候,用最小二乘法估计的模型参数就会不稳定,回归系数的估计值很容易引起误导或者导致错误的结论。所以,需要勾选“共线性诊断”来做判断
通过容许度可以计算共线性的存在与否?容许度TOL=1-RI平方或方差膨胀因子
(VIF): VIF=1/1-RI平方,其中RI平方是用其他自变量预测第I个变量的复相关系数,显然,VIF为TOL的倒数,TOL的值越小,VIF的值越大,自变量XI与其他自变量之间存在共线性的可能性越大。
提供三种处理方法:
1:从有共线性问题的变量里删除不重要的变量
2:增加样本量或重新抽取样本。
3:采用其他方法拟合模型,如领回归法,逐步回归法,主成分分析法。
再点击“绘制”选项,如下所示:
上图中:
DEPENDENT( 因变量) ZPRED(标准化预测值) ZRESID(标准化残差) DRESID(剔除残差) ADJPRED(修正后预测值) SRSID(学生化残差) SDRESID(学生化剔除残差) 一般我们大部分以“自变量”作为 X 轴,用“残差”作为Y轴,但是,也不要忽略特殊情况,这里我们以“ZPRED(标准化预测值)作为
再点击”保存“按钮,进入如下界面:
如上图所示:勾选“距离”下面的“cook距离”选项(cook 距离,主要是指:把一个个案从计算回归系数的样本中剔除时所引起的残差大小,cook距离越大,表明该个案对回归系数的影响也越大)
在“预测区间”勾选“均值”和“单值” 点击“继续”按钮,再点击“确定按钮,得到如下所示的分析结果:(此分析结果,采用的是“逐步法”得到的结果)
SPSS—回归—多元线性回归结果分析(二)
,最近一直很忙,公司的潮起潮落,就好比人生的跌岩起伏,眼看着一步步走向衰弱,却无能为力,也许要学习“步步惊心”里面“四阿哥”的座右铭:“行到水穷处”,”坐看云起时“。 接着上一期的“多元线性回归解析”里面的内容,上一次,没有写结果分析,这次补上,结果分析如下所示:
结果分析1:
由于开始选择的是“逐步”法,逐步法是“向前”和“向后”的结合体,从结果可以看出,最先进入“线性回归模型”的是“price in thousands
结果分析:
1:从“模型汇总”中可以看出,有两个模型,(模型1和模型2)从R2 拟合优度来看,模型2的拟合优度明显比模型1要好一些
(0.422>0.300)
2:从“Anova
不可解释的误差)
由于“回归平方和”跟“残差平方和”几乎接近,所有,此线性回归模型只解释了总平方和的一半,
3:根据后面的“F统计量”的概率值为0.00,由于0.00
结果分析:
1:从“已排除的变量”表中,可以看出:“模型2”中各变量的T检的概率值都大于“0.05”所以,不能够引入“线性回归模型”必须剔除。
从“系数a” 表中可以看出:
1:多元线性回归方程应该为:销售量=-1.822-0.055*价格+0.061*轴距
但是,由于常数项的sig为(0.116>0.1) 所以常数项不具备显著性,所以,我们再看后面的“标准系数”,在标准系数一列中,可以看到“常数项”没有数值,已经被剔除
所以:标准化的回归方程为:销售量=-0.59*价格+0.356*轴距
2:再看最后一列“共线性统计量”,其中“价格”和“轴距”两个容差和“vif都一样,而且VIF都为1.012,且都小于5,所以两个自变量之间没有出现共线性,容忍度和
膨胀因子是互为倒数关系,容忍度越小,膨胀因子越大,发生共线性的可能性也越大
从“共线性诊断”表中可以看出:
1:共线性诊断采用的是“特征值”的方式,特征值主要用来刻画自变量的方差,诊断自变量间是否存在较强多重共线性的另一种方法是利用主成分分析法,基本思想是:如果自变量间确实存在较强的相关关系,那么它们之间必然存在信息重叠,于是就可以从这些自变量中提取出既能反应自变量信息(方差),而且有相互独立的因素(成分)来,该方法主要从自变量间的相关系数矩阵出发,计算相关系数矩阵的特征值,得到相应的若干成分。
从上图可以看出:从自变量相关系数矩阵出发,计算得到了三个特征值(模型2中),最大特征值为2.847,最小特征值为0.003
条件索引=最大特征值/相对特征值再进行开方(即特征值2的条件索引为 2.847/0.150 再开方=4.351)
标准化后,方差为1,每一个特征值都能够刻画某自变量的一定比例,所有的特征值能将刻画某自变量信息的全部,于是,我们可以得到以下结论:
1:价格在方差标准化后,第一个特征值解释了其方差的0.02,第二个特征值解释了0.97,第三个特征值解释了0.00
2:轴距在方差标准化后,第一个特征值解释了其方差的0.00,第二个特征值解释了0.01,第三个特征值解释了
0.99
可以看出:没有一个特征值,既能够解释“价格”又能够解释“轴距”所以“价格”和“轴距”之间存在共线性较弱。前面的结论进一步得到了论证。(残差统计量的表中数值怎么来的,这个计算过程,我就不写了)
从上图可以得知:大部分自变量的残差都符合正太分布,只有一,两处地方稍有偏离,如图上的(-5到-3区域的)处理偏离状态
范文四:多元线性回归分析实例分析
王华丽
湖北襄阳 441052 )( 湖北文理学院数学与计算机科学学院
摘 要:多元线性回归是简单线性回归的推广,研究的是一个变量与多个变量之间的依赖关系。作为质量统计软件领域的领导者,MINITAB 是一个精确的、强大的、使用方便的统计软件。多元回归分析预测法,是指通过对两个或两个以上的自变量与一个因变量的相关分 析,建立 预测模型进行预测的方法。当自变量与因变量之间存在线性关系时,称为多元线性回归分析。该文通过一个具体实例介绍如何运用 MINITAB软件,建立儿子身高与父母身高、年锻炼次数的多元线性回归模型,并对MINITAB的输出结果进行分析,得出方程效果良好的结论。 关键词:MINITAB软件 多元线性回归 显著性 实例分析
中图分类号:O212 文献标识码: A文章编号:1672-3791(2014)10(b)-0022-02 回归分析是数据分析中使用很多的一 领导者,全球六西格玛实施的共同语言,它 量), y 是因变量,多元线性回归模型的理 种方法 。回归分析是定量的给出变量间的 以无可比拟的强大功能和简易的可视化操 论假设是 变化规律,它不仅提供变量间的回归方程, 作获得了广大质量学者和统计专家的青 , y t t x t x t x s 而且可以判断所建立回归方程的有效性。 睐 。MINITAB 软件是为质量改善 、教育和 0 1 1 2 2 p p 2 在方程有效性的前提下, 可以用方程做预 研究应用领域提供统计软件和服务, 是质 ,s ~ N (0,o ) 测和控制,并了解预测和控制的精度。多元 量管理和六西格玛实施软件工具, 更是持 回归分析预测法, 是指通过对两个或两个 , t, t, , t t其中, 是 p 1 个未知参 0 1 2 p 续质量改进的良好工具软件。 以上的自变量与一个因变量的相关分析 , t , t , , t 数, t 0 称为回归常数, 1 2 p 称为回归 建立预测模型进行预测的方法 。当自变量 2 与因变量之间存在线性关系时, 称为多元 系数, 为随机误差。s ~ N (0,o ) 1 多元线性回归分析的一般模型线性回归分析。 多元线性回归分析的一般模型为: 设 MINITAB 软件是现代质量管理统计的 2 MINITAB 软件建立模型x, x, , x 是 p ( 2 ) 个自变量 ( 解释变 1 2 p 下面通过一个实例来详细讲解, 如何
运用MINITAB软件进行多元线性回归 。现 表 1 父母身高与儿子身高 抽取20 个家庭调查资料的部分变量,数据1 母亲身高(cm ) X 2 年参加锻炼次数 X 3 儿子身高(cm ) Y 编号 父亲身高(cm ) X 见表1,试对父母身高与儿子身高进行回归 1 172 163 90 176 分析。 2 171 159 70 172 使用MINITAB 软件, 输入表 1中数据 , 3 169 158 50 170 选择指令“统计,回归,回归”, 在出现界 4 171 161 65 174 面输入相应的变量名;打开“图形”窗,选择 5 167 159 50 169 “四合一”及在“残差与变量”中填入各自变6 172 163 100 177 量名称;打开“存储”窗,选择“残差”、“标准 7 172 160 60 171 化残差”及“拟合值”,点击“确定”后,得到 8 170 162 70 173 输出结果。 9 175 166 110 182 MINITAB 输出结果 : 10 179 166 100 183 回归方程: 11 176 164 90 180 儿子身高=-23.7+0.303父亲身高+0.12 171 159 80 174 880母亲身高+0.0593锻炼次13 167 158 60 172 数14 176 163 70 177 S=1.11974 R-sq=96.33% R-sq(调整)15 172 162 70 175 =95.65% 16 181 169 90 186 回归方程拟合出来以后, 我们要解决 以下几个问题:(1)给出方程显著性检验,从 17 174 167 80 182 总体上判定回归方程有效与否。(2)给出方 18 170 161 70 174 程总效果好坏的度量。(3)在回归方程效果 19 183 169 120 187 显著时,对各个回归系数进行显著性检验, 20 176 165 110 182 将效应不显著的自变量删除,以优化模型, 这点在多元回归中尤为重要。(4)残差诊断, 表 2 回归系数显著性检验表 检验数据是否符合回归的基本假定, 检验 项 系数 系数标准误 T 值 P 值 整个回归模型与数据拟合的是否很好 ,可 常量 - 23.7 18.9 - 1.25 0.228 否进一步改进回归方程来优化现有模型。 父亲身高 0.303 0.137 2.22 0.042
母亲身高 0.880 0.181 4.85 0.000 3 MINITAB 输出结果分析锻炼次数 0.0593 0.0215 2.76 0.014 如何判断整个回归方程是否有意义,
表 3 ANOVA分析表 就要进行回归方程显著性检验, 也就是要 检验下列问题:H :模型无意义,H 模型有 A dj SS A dj MS F 值 P 值 0 1 来源 自由度 意义。本例(表3)ANOVA表中P =0,回归 3 527.139 175.713 140.14 0.000 0.05, 所以拒绝H :模型无意义,接受H 模型有意 父亲身高 1 6.159 6.159 4.91 0.042 0 1 义。说明在显著性水平a=0.05下,线性回母亲身高 1 29.521 29.521 23.54 0.000 归 锻炼次数 1 9.578 9.578 7.64 0.014 方程总效果是显著的。 如果实际观测值误差 16 20.061 1.254 与拟合出来的回归线 合计 19 547.200 (下转 24 页)
科技资讯 SCIENCE & TECHNOLOGY INFORMATION 22
2014 NO.29 SCIENCE & TECHNOLOGY INFORMATION 信 息 技 术
集。不论硬件电路结构或显示程序都要简
洁得多,且该模块的价格也较低。 2.5 报警电路
报警电路采用语音芯片直接驱动喇叭
的方式,用于实时播报当前湿度,以及土壤
湿度低于设定湿度范围时的语音警报 ,由
单片机控制其输出报警信号(图4)。
3 软件设计该系统软件部分采用C语言编程,首图 4 报警电路 先 进行系统初始化, 模式选择后确定湿度
设 定范围, 检测当前湿度值与设定范围进
行 比较 , 如果在范围内 , 则输出湿度值及
文 字、语音提醒; 若低于设定值, 则输出湿
度 值并发出文字、语音报警信息,及时提
醒为
盆栽浇水,程序流程图如图5所示。
4 结语该设计用单片机控制技术指导操作者
科学地为盆栽浇水 ,使盆栽照料工作变得
更加轻松愉快。系统采用集成了AD 转换模 块的单片机作为控制核心 , 并采用液晶显
示模块显示提醒及报警信息, 简化了硬件
电路 , 降低了电路板的体积 , 而且操作方
便。
参考文献[1] 方泽鹏,黄双萍,陈仲涛.基于单片机的
花盆土壤湿度控制系统设计[J].现代农
业装备,2013(4):41-45. 张玮,王东[2] 锋.基于AT89S51单片机的 微型土壤
湿度检测仪设计[J].机电产品 开发与
创新,2010(7):74-75. 侯殿有.单片机
C语言程序设计[M]. 北 图 5 系统程序流程图 [3] 京:人民邮电出版社,2010.范围也不同,根据盆栽所需土壤的合适湿度 以及警示信息 。该设计中的显示模块采用 [4] 郭天祥.新概念51单片机C语言教程范围,可将盆栽大致分为湿生花卉、中生花 带中文字库的12864LCD液晶显示屏,如入 门、提高、开发、拓展全攻略[M].电卉、耐旱花卉三种。模式选择模块用于选择 图子工 业出版社,2009. 所监测盆栽的湿度类型,从而确定该盆栽的 3,它是一种具有4位/8位并行、2线或3
湿度监测范围。该部分电路用按键实现。 线串 行多种接口方式,内部含有国标一级、
二级 简体中文字库的点阵图形液晶显示2.4 湿度显示模块 湿度显示模块用于显示当前湿度值,模块 ; 其显示分辨率为 128 × 64, 内置
8192 个
16*16点汉字,和128个16*8 点ASCII 字y=-23.7+0.303x +0.880x +0.0593x (上接 22 页) 要的指标, 那个S 最小, 哪个回归方程就最 符1 2 3 模型中,X 系数0.303表示:如果父亲比小。 很接近,就说明回归线与数据拟合的很好, 1 从本例输出结果看R 96.33%,R同一代人的平均身高多1cm,那么他的儿子 就可以说回归方程的总效果很好。(表2)我 sq sq(adj) =95.65%来看,两者很接近,S=1.11974 比 将比儿子那一代人的平均身高多出0.303 cm; 们通常用R 、R 、S作为回归方程总效果 sq sq(adj) 较小, 模型还可以。X 的系数解释也是如此;X 的系数表示参加 的度量, 以此来比较几种回归方程效果的 2 3 体育锻炼的次数和身高之间存在正相关 ; 好坏。R 是回归平方和占离差平方和的比 回归方程显著时, 做回归系数显著性 sq 常数项一般没有与它相对应的实际意义上 率, 其数值越接近1 代表模型拟合的越好。 检验,一般假设 H :β=0,H :β?0,若P, 0 1 当然R 并不是回归模型拟合效果的最好度 0.05,则回归系数不为零,说明系数对应的 的解释。 sq 量指标,因为当多一个自变量加入模型时, 自变量是显著的。当只有一个自变量时,回
归方程显著性检验与回归系数检验是等价 不管这个自变量是否显著 , 回归平方和就参考文献[1] 的,但是当自变量不止一个时,回归总效果 张海燕.基于多元线性回归模型的四川 会增大,R 也会增大,这样就看不出新增加 sq 显著不能排除某几个变量是无意义的 。我 农村居民收入增长分析[J].统计观察,的自变量是否有意义, 这点在多元回归中 2010(13):88-90. 孙雪飞.回归分析在 更为明显。因此我们用R 去修正R ,以考 们进行回归方程系数检验的目的, 就是要sq(adj) sq [2] 虑总项数给模型带来的影响。R ?R 两 房地产销售中的应 用[J].科技咨询导找出是否有“滥竽充数 ”的自变量, 把这些 sq(adj) sq 报,2007(26):168- 者数值越接近越好 ,另一个指标是残差标 多余的自变量从方程中删除掉, 以修正现
169. 马逢时.六西格玛管理统计指南有模型。 准差 , 它是从观察值与拟合回 [3] 从本例输出结果看到三个自变量P 值 [M].北 京:中国人民大学出版归线的平均偏离程度来度量的, 也是回归 都小于0.05,故三个都为显著因子。 社,2012. 模型中标准差σ的估计值 。对于几个不 综上所述: 我们认为模型为同 的回归方程的效果加以比较时,S是个
最重
科技资讯 SCIENCE & TECHNOLOGY INFORMATION 24
范文五:多元线性回归分析实例及教程
多元线性回归分析预测法概述
在市场的经济活动中,经常会遇到某一市场现象的发展和变化取决于几个影响因素的情况,也就是一个因变量和几个自变量有依存关系的情况。而且有时几个影响因素主次难以区分,或者有的因素虽属次要,但也不能略去其作用。例如,某一商品的销售量既与人口的增长变化有关,也与商品价格变化有关。这时采用一元回归分析预测法进行预测是难以奏效的,需要采用多元回归分析预测法。
多元回归分析预测法,是指通过对两上或两个以上的自变量与一个因变量的相关分析,建立预测模型进行预测的方法。当自变量与因变量之间存在线性关系时,称为多元线性回归分析。
[编辑]
多元线性回归的计算模型[1]
一元线性回归是一个主要影响因素作为自变量来解释因变量的变化,在现实问题研究中,因变量的变化往往受几个重要因素的影响,此时就需要用两个或两个以上的影响因素作为自变量来解释因变量的变化,这就是多元回归亦称多重回归。当多个自变量与因变量之间是线性关系时,所进行的回归分析就是多元性回归。
设y为因变量,
元线性回归模型为:
其中,b0为常数项,为回归系数,b1为 固定时,x1每增加一
固定时,x2每增加一为自变量,并且自变量与因变量之间为线性关系时,则多个单位对y的效应,即x1对y的偏回归系数;同理b2为
相关时,可用二元线性回归模型描述为:
其中,b0为常数项, 为回归系数,b1为个单位对y的效应,即,x2对y的偏回归系数,等等。如果两个自变量x1,x2同一个因变量y呈线固定时,x2每增加一个单位对y的效应,即x2对y的偏回归系数,等等。如果两个自变量x1,x2同一个因变量y呈线相关时,可用二元线性回归模型描述为:
y = b0 + b1x1 + b2x2 + e
建立多元性回归模型时,为了保证回归模型具有优良的解释能力和预测效果,应首先注意自变量的选择,其准则是:
(1)自变量对因变量必须有显著的影响,并呈密切的线性相关;
(2)自变量与因变量之间的线性相关必须是真实的,而不是形式上的;
(3)自变量之彰应具有一定的互斥性,即自变量之彰的相关程度不应高于自变量与因变量之因的相关程度;
(4)自变量应具有完整的统计数据,其预测值容易确定。
多元性回归模型的参数估计,同一元线性回归方程一样,也是在要求误差平方和()为最小的前提下,用最小二乘法求解参数。以二线性回归模型为例,求解回归参数的标准方程组为
解此方程可求得b0,b1,b2的数值。亦可用下列矩阵法求得
即
[编辑]
多元线性回归模型的检验[1]
多元性回归模型与一元线性回归模型一样,在得到参数的最小二乘法的估计值之后,也需要进行必要的检验与评价,以决定模型是否可以应用。
1、拟合程度的测定。
与一元线性回归中可决系数r2相对应,多元线性回归中也有多重可决系数r2,它是在因变量的总变化中,由回归方程解释的变动(回归平方和)所占的比重,R2越大,回归方各对样本数据点拟合的程度越强,所有自变量与因变量的关系越密切。计算公式为:
其中,
2.估计标准误差
估计标准误差,即因变量y的实际值与回归方程求出的估计值之间的标准误差,估计标准误差越小,回归方程拟合程度越程。
其中,k为多元线性回归方程中的自变量的个数。
3.回归方程的显著性检验
回归方程的显著性检验,即检验整个回归方程的显著性,或者说评价所有自变量与因变量的线性关系是否密切。能常采用F检验,F统计量的计算公式为:
根据给定的显著水平a,自由度(k,n-k-1)查F分布表,得到相应的临界值Fa,若F > Fa,则回归方程具有显著意义,回归效果显著;F
4.回归系数的显著性检验
在一元线性回归中,回归系数显著性检验(t检验)与回归方程的显著性检验(F检验)是等价的,但在多元线性回归中,这个等价不成立。t检验是分别检验回归模型中各个回归系数是否具有显著性,以便使模型中只保留那些对因变量有显著影响的因素。检验时先计算统计量ti;然后根据给定的显著水平a,自由度n-k-1查t分布表,得临界值ta或ta / 2,t > t ? a或ta / 2,则回归系数bi与0有显著关异,反之,则与0无显著差异。统计量t的计算公式为:
其中,Cij是多元线性回归方程中求解回归系数矩阵的逆矩阵(x'x) ? 1的主对角线上的第j个元素。对二元线性回归而言,可用下列公式计算:
其中,
5.多重共线性判别
若某个回归系数的t检验通不过,可能是这个系数相对应的自变量对因变量的影平不显著所致,此时,应从回归模型中剔除这个自变量,重新建立更为简单的回归模型或更换自变量。也可能是自变量之间有共线性所致,此时应设法降低共线性的影响。
多重共线性是指在多元线性回归方程中,自变量之彰有较强的线性关系,这种关系若超过了因变量与自变量的线性关系,则回归模型的稳定性受到破坏,回归系数估计不准确。需要指出的是,在多元回归模型中,多重共线性的难以避免的,只要多重共线性不太严重就行了。判别多元线性回归方程是否存在严惩的多重共线性,可分别计算每两个自变量之间的可决系数r2,若r2 > R2或接近于R2,则应设法降低多重线性的影响。亦可计算自变量间的相关系数矩阵的特征值的条件数k = λ1 / λp(λ1为最大特征值,λp为最小特征值),k
100≤k≤1000,则自变量间存在较强的多重共线性,若k>1000,则自变量间存在严重的多重共线性。降低多重共线性的办法主要是转换自变量的取值,如变绝对数为相对数或平均数,或者更换其他的自变量。
6.D.W检验
当回归模型是根据动态数据建立的,则误差项e也是一个时间序列,若误差序列诸项之间相互独立,则误差序列各项之间没有相关关系,若误差序列之间存在密切的相关关系,则建立的回归模型就不能表述自变量与因变量之间的真实变动关系。D.W检验就是误差序列的自相关检验。检验的方法与一元线性回归相同。
[编辑]
多元线性回归分析预测法案例分析
[编辑]
案例一:公路客货运输量多元线性回归预测方法探讨[2]
一、背景
公路客、货运输量的定量预测,近几年来在我国公路运输领域大面积广泛地开展起来,并有效的促进了公路运输经营决策的科学化和现代化。
关于公路客、货运输量的定量预测方法很多,本文主要介绍多元线性回归方法在公路客货运输量预测中的具体操作。根据笔者先后参加的部、省、市的科研课题的实践,证明了多元线性回归方法是对公路客、货运输量预测的一种置信度较高的有效方法。
二、多元线性回归预测
线性回归分析法是以相关性原理为基础的.相关性原理是预测学中的基本原理之一。由于公路客、货运输量受社会经济有关因素的综合影响。所以,多元线性回归预测首先是建立公路客、
货运输量与其有关影响因素之间线性关系的数学模型。然后通过对各影响因素未来值的预测推算出公路客货运输量的预测值。
三、公路客、货运输量多元线性回归预测方法的实施步骤
1.影响因素的确定
影响公路客货运输量的因素很多,主要包括以下一些因素:
(1)客运量影响因素
人口增长量裤保有量、国民生产总值、国民收入工农业总产值,基本建设投资额城乡居民储蓄额铁路和水运客运量等。
(2)货运量影响因素
人口货车保有量(包括拖拉机),国民生产总值,国民收入、工农业总产值,基本建设投资额,主要工农业产品产量,社会商品购买力,社会商品零售总额.铁路和水运货运量菩。
上述影响因素仅是对一般而言,在针对具体研究对象时会有所增减。因此,在建立模型时只须列入重要的影响因素,对于非重要因素可不列入模型中。若疏漏了某些重要的影响因素,则会造成预测结果的失真。另外,影响因素太少会造成模型的敏感性太强.反之,若将非重要影响因素列入模型,则会增加计算工作量,使模型的建立复杂化并增大随机误差。
影响因素的选择是建立预测模型首要的关键环节,可采取定性和定量相结合的方法进行.影响因素的确定可以通过专家调查法,其目的是为了充分发挥专家的聪明才智和经验。
具体做法就是通过对长期从事该地区公路运输企业和运输管理部门的领导干部、专家、工作人员和行家进行调查。可通过组织召开座谈会.也可以通过采访,填写调查表等方法进行,从中选出主要影响因素为了避免影响因素确定的随意性,提高回归模型的精度和减少预测工作量,可通过查阅有关统计资料后,再对各影响因素进行相关度(或关联度)和共线性分析,从而再次筛选出最主要的影响因素.所谓相关度分析就是将各影响因素的时间序列与公路客货运量的时间序列做相关分杯事先确定—个相关系数,对相关系数小于的影响因素进行淘汰.关联度是灰色系统理论中反映事物发展变化过程中各因素之间的关联程度,可通过建空公路客、货运量与各影响影响因素之间关联系数矩阵,按一定的标准系数舍去关联度小的影响因素.所谓共线性是指某些影响因素之问存在着线性关系或接近于线性关系.由于公路运输经济自身的特点,影响公路客,货运输量的诸多因素之问总是存在着一定的相关性,持别是与国民经济有关的一些价值型指标。 我们研究的不是有无相关性问题而是共线性的程度,如果影响因素之间的共线性程度很高,首先会降低参数估计值的精度。其次在回归方程建立后的统计检验中导致舍去重要的影响因素或错误的地接受无显著影响的因素,从而使整个预测工作失去实际意义。关于共线性程度的判定,可利用逐步分析估计法的数理统计理论编制计算机程序来实现。或者通过比较rij和R2的大小来判定。在预测学上,一般认为当rij > R2时,共线性是严重的,其含义是,多元线性回归方程中
所含的任意两个自变量xi,xj之间的相关系数rij大于或等于该方程的样本可决系数R2时,说明自变量中存在着严重的共线性问题。
2.建立经验线性回归方程利用最小二乘法原理寻求使误差平方和达到撮小的经验线性回归方程:
y——预测的客、货运量
g——各主要影响因数
3.数据整理
对收集的历年客、货运输量和各主要影响因素的统计资料进行审核和加工整理是为了保证预测工作的质量。
资料整理主要包括下列内容:
(1)资料的补缺和推算。
(2)对不可靠资料加以核实调整.对查明原因的异常值加以修正。
(3)对时间序列中不可比的资料加以调整和规范化;对按当年价格计算的价值指标应折算成按统。
4.多元线性回归模型的参数估计
在经验线性回归模型中,
参数的估计值进行检验。
此项工作的目的在于判定估计值是否满意、可靠。一般检验工作须从以下几方面来进行。
? 经济意义检验 是要估计的参数,可通过数理统计理论建立模型来确定。在实际预测中,可利用多元线性回归复相关分析的计算机程序来实现·5.对模型
关于经济预测的数学模型,首先要检验模型是否有经济意义,γp若参数估计值的符号和大小与公路运输经济发展以及经济判别不符合时,这时所估计的模型就不能或很难解释公路运输经济的一般发展规律.就应抛弃这个模型.需要重新构造模型或重新挑选影响因素。
? 统计检验
统计检验是数理统计理论的重要内容,用于检验模型估计值的可靠性。通常,在公路客、货运量预测中应采用的统计检验是:
? 拟合度检验
所谓拟合度是指所建立的模型与观察的实际情况轨迹是否吻合、接近,接近到什么程度。统计学是通过构造统计量R2来量度的,R2可由样本数据计算得出。若建立的模型愈接近于实际,则R^2愈接近于1。
? 回归方程的显著性检验
回归方程的显著性检验是通过方差分析构造统计量F来进行的,统计量F是通过样本数据计算得出的。当给定某一置信度后,可以通过查阅F表来确定回归模型从总体效果来看是否可以采纳。
? 参数估计值的标准差检验
估计值的标准差是衡量估计值与真实参数值的离差的一种量度。参数的标准差越大,估计值的可靠性也就越小;反之,如果标准差越小,那么估计值的可靠性也就越大。参数值标准差的检验,可以通过构造大统计量来进行量度。当给定某一置信度后,可以通过查表来确定模型中某个参数估计值的可靠性。
应当强调指出.统计检验相对于经济意义检验来说是第二位的。如果经济意义检验不合理,那么即使统计检验可以达到很高的置信度,也应当抛弃这种估计结果,因为用这样的结果来进行经济预测是没有意义的。
6.最优回归方程的确定
经过上述的经济意义和统计检验后,挑选出的线性回归方程往往是好几个、为了从中优选出用于进行实际预测的方程,我们可以采用定性和定量相结合的办法。
从数理统计的原理来讲,应挑选方程的剩余均方和S·E较小为好.但作为经济预'删还必须尽量考虑到方程中的影响因素更切合实际和其未来值更易把握的原则来综合考虑。当然、有时也可以从中挑选出好几个较优的回归方程.通过预测后,分别作为不同的高、中、低方案以供决策人员选择。
7.模型的实际预测检验
在获得模型参数估计值后,又经过了上述一系列检验而选出的最优(或较优)回归方程,还必须对模型的预测能力加以检验。不难理解、最优回归方程对于样本期间来说是正确的,但是对用于实际预测是否合适呢?为此,还必须研究参数估计值的稳定性及相对于样本容量变化时的灵敏度,也必须研究确定估计出来的模型是否可以用于样本观察值以外的范国,其具休做法是:
(1)采用把增大样本容量以后模型估计的结果与原来的估计结果进行比较,并检验其差异的显著性。
(2)把估计出来的模型用于样本以外某一时间的实际预测,并将这个预测值与实际的观察值作一比较,然后检验其差异的显著性。
8.模型的应用
公路客、货运输量多元线性回归预测模型的研究目的主要有以下几个方面。
(1)进行结构分析,研究影响该地区的公路客、货运输量的主耍因素和各影响因素影响程度的大小,进一步探讨该地区公路运输经济理论。
(2)预测该地区今后年份的公路客、货运输量的变化,以便为公路运输市场、公路运输政策及公路运辅建设项目投资作出正确决策提供理论依据。另外,还可以通过公路客.货运输量与公路交通量作相关分析来对公路的饱和度发展趋势进行预测。从而为公路的新建、扩建项目的投资提供决策分析。
(3)模拟各种经济政策下的经济效果,以便对有关政策进行评价。
四、经调查分析,影响某地区旅客运输量的因素为。
x1——国民收入
x2——工农业总产值
x3——社会总产值
x4——人口
x5——客车保有量
x6——城乡居民储蓄存款
经计算得下列相关系数表:
Y——客运盈
Z——旅客周转量
若令α = 0.85,则可以舍去x6这个影响因索,也就是认为“城乡居民储蓄存款”不能作为响旅客运输量的主要因素。
2.经调查分析、影响某地区旅客运输量的因素为: x1——国民收入
x2——工农业总产值
x3——社会总产值
x4——人口
x5——客车保有量
x6——国民生产总值
x7——公路通车里程
经计算得客运量和旅客周转量的经验线性回归方程如下: Y = α0 + α1x1 + α2x2 + α5x5 R^2=0.9997
Z = β0 + β4x4 + β5x5 + β7x7 R^2=0.9983 R^2=0.9962
Y——客运盈
Z——旅客周转量
各自变量问的相关系数表如下: R2 = 0.9990
由上述计算可知,四个方程中均未出现rij > R2的情况.因此可以认为各自方程中的影响因素之间不存在严重共线性问题。
3.经调查分析,影响某地区货运周转量的因素为: x1——国民收入
x2——工农业总产值
x3——基建投资额
x4——原煤产量
x5——钢铁、化肥、水泥、粮食总产量
x6——国民总产值
x7——社会商品零售总额
x8——相邻地、市工农业总产值的平均值 Y = a0 + a4x4 + a6x6 + a7x7 (1)
其中:R2=0.9875 F=206.33 S·E=1673.24 t4=-2.8321 t6=3.1407 t7=2.7431
Y = b0 + b2x2 + b4x4 (2)
其中:R2=0.9764 F=164.59 S·E=1044.27
转载请注明出处范文大全网 » 多元线性回归分析实例

